

Swift Regex Deep Dive
iOS MacOur introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.
Core ML is an exciting new framework that makes running various machine learning and statistical models on macOS and iOS feel natively supported. The framework helps developers to integrate already prepared statistical and machine learning models into their apps. It builds on top of Apple’s lower-level machine learning primitives, some of which were announced at WWDC 2016.
coremltools, which is a Python package designed to help generate an .mlmodel file that Xcode can use.After reading this post, you will get an introduction to the life cycle of working with Core ML. You will create a model in Python, generate the .mlmodel file, add it to Xcode and use this model via Core ML to run it on a device. Let’s get started!
Core ML supports a wide variety of models. In supporting these models, Core ML expects us to create them in a few set environments. This helps to delimit the support domain for the coremltools package that we need to use to generate our .mlmodel file.
In this app, we will use scikit-learn to develop a linear regression model to predict home prices. scikit-learn is a Python package built on top of NumPy, SciPy, and matplotlib that is designed for general purpose data analysis. Our regression model to predict housing prices will be based upon two predictor variables.
An aside: our goal is not to create the most accurate model. Instead, our purpose in this post is to develop something plausible that we can showcase in an app. Model building is difficult, and this isn’t the right post for a deep dive into model selection and performance.
The model we will develop will take the following form: 𝑦 = α + β₁𝑥₁ + β₂𝑥₂ + 𝑒
Our variable y is the dependent variable we seek to predict: housing prices. x1 is an independent variable that will represent crime rates. x2 is an independent variable that represents the number of rooms in a house. e is an error term representing the disparity between the model’s prediction for a given record in the data set and its actual value. We won’t actually model this parameter, but include it in the model’s specification above for the sake of completeness.
α, β₁, and β₂ are coefficients (technically, α is called the intercept) that the model will estimate to help us generate predictions. Incidentally, it is these parameters that make our model linear. y is the result of a linear combination of the coefficients and the independent variables.
If you don’t know what regression is, that’s okay. It is a foundational model in statistics and machine learning. The main goal of regression is to draw a line through data. In so doing, the model seeks to estimate the necessary parameters needed for line drawing.
Remember the formula y = mx + b? y is the y-coordinate, m is the slope, x is the x-coordinate, and b is the intercept. Recalling these will give you a good intuition for what regression is doing.
For example, consider this plot:
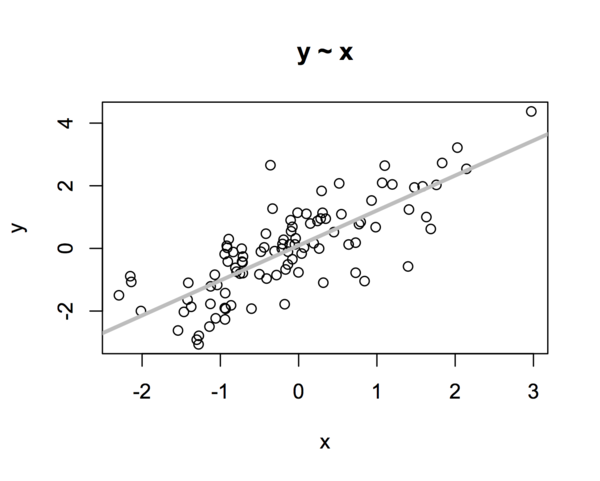
The chart shows two variables, x and y, that I generated randomly from the Normal Distribution. Each has 100 samples. x is distributed with a mean of 0, and a standard deviation of 1: x ~ N(0, 1). y is generated with a mean of x and a standard deviation of 1: y ~ N(x, 1). That is, each y is generated by drawing a sample for the Normal Distribution whose mean is x. For example, the first value for y is generated by sampling from the Normal Distribution whose mean is the first value in x.
Generating y in this way helps to make the association between the two variables.
Next, I performed a bivariate regression to estimate the intercept and slope that define the relationship between y and x. The line drawn on the chart above shows the result of that model. In this case, it’s a pretty good fit for the data, which we would expect given that y was defined as a function of x plus some random noise that came from sampling from the Normal Distribution.
So, at the risk of being somewhat reductive, regression is all about drawing lines. If you’re curious to learn more about drawing lines, take a look at our post on machine learning.
The data for this post come from a study by Harrison and Rubinfeld (1978) and are open to the public. The data set comprises 506 observations on a variety of factors the authors collected to predict housing prices in the Boston area. It comes with the following predictors (the first five records):
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0
PTRATIO B LSTAT
0 15.3 396.90 4.98
1 17.8 396.90 9.14
2 17.8 392.83 4.03
3 18.7 394.63 2.94
4 18.7 396.90 5.33
The dependent variable looks like (again, the first five records):
MEDV
0 24.0
1 21.6
2 34.7
3 34.4
4 36.2
The dependent variable shows the median value of the home’s price in units of $1,000. The data are from the 1970s, and so even tacking on a few zeros to these prices is still enviably low!
With an understanding of what the data looks like, it’s time to write the regression model.
We define the regression model in Python 2.7. This is what coremltools needs. Here is the code that defines the model:
import coremltools
from sklearn import datasets, linear_model
import pandas as pd
from sklearn.externals import joblib
# Load data
boston = datasets.load_boston()
boston_df = pd.DataFrame(boston.data)
boston_df.columns = boston.feature_names
# Define model
X = boston_df.drop(boston_df.columns[[1,2,3,4,6,7,8,9,10,11,12]], axis=1)
Y = boston.target
lm = linear_model.LinearRegression()
lm.fit(X, Y)
# coefficients
lm.intercept_
lm.coef_
# Convert model to Core ML
coreml_model = coremltools.converters.sklearn.convert(lm, input_features=["crime", "rooms"], output_feature_names="price")
# Save Core ML Model
coreml_model.save("BostonPricer.mlmodel")
You don’t need to be very familiar with Python to be able to follow along. The top part of this file imports the necessary packages.
Next, we load the Boston housing data, and perform a little bit of clean up to make sure that our model has the dependent and independent variables it needs. With the variables in hand, we can create our linear regression model: lm = linear_model.LinearRegression(). Once we have created the model, we can fit it with our data: lm.fit(X, Y). Fitting the data will generate the coefficients we need to create predictions from new data in our app. The .mlmodel will give us access to these coefficients to make those predictions.
The last two lines of the Python code convert the linear model to the .mlmodel format and save it out to a file.
coremltools.converters.sklearn.convert(lm, ["crime", "rooms"], "price") does the conversion. coremltools provides a number of converters that you can use to convert your models to the .mlmodel format. See here for more details. Download the documentation on that page to see more information about converting.
Run python NAME_OF_FILE.py to generate the BostonPricer.mlmodel. For example, my file name is “pricer_example.py,” so I ran python pricer_example.py. Make sure to run this from within the same directory as your Python script file. Your .mlmodel file will be created in this same location.
Our iOS app will be a simple single view application. It will provide a pretty sparse user interface to generate predictions of housing prices based on our two independent variables. The single view will have a UIPickerView with two components, one for crime rates and one for rooms. It will also have a label to show the prices predicted from the inputs selected in the picker.
The app will look like this:
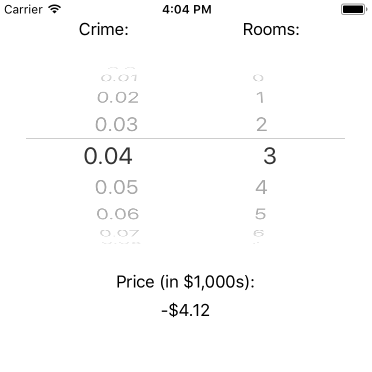
We won’t go through setting up the UI in the storyboard. Feel free to take a look at the associated Xcode project if you’re curious.
BostonPricer.mlmodel to an Xcode ProjectDrag and drop the .mlmodel file into your Xcode project in the usual way. For example, you can drop it into your Project Navigator. This creates a nice interface to view some details about your model from within Xcode. You can view this interface by clicking on your BostonPricer.mlmodel file in Xcode.
Adding this model file also automatically created a few generated classes named BostonPricer, BostonPricerInput and BostonPricerOutput.
BostonPricer can be used to create an instance of your model. It provides an API for you to call into it to produce predictions.BostonPricerInput is a class that you can use to create input data to pass to an instance of your model type, BostonPricer. The model will use this information to generate a prediction. You can work with this type if you like, but it isn’t necessary. BostonPricer also provides a method to generate a prediction from the data types that match your input variables. More on this soon.BostonPricerOutput is a class that models the output of your model based upon some input. You use this generated type to work with the prediction your model produces.The class definitions are somewhat hidden from you, but you can find them if you ‘command-click’ on BostonPricer. A pop up will appear that will give you the option to “Jump to Definition”. Select “Jump to Definition” and Xcode will take you BostonPricer’s implementation. The other generated class definitions are located in the same file. It should look like this:
@objc class BostonPricer:NSObject {
var model: MLModel
init(contentsOf url: URL) throws {
self.model = try MLModel(contentsOf: url)
}
convenience override init() {
let bundle = Bundle(for: BostonPricer.self)
let assetPath = bundle.url(forResource: "BostonPricer", withExtension:"mlmodelc")
try! self.init(contentsOf: assetPath!)
}
func prediction(input: BostonPricerInput) throws -> BostonPricerOutput {
let outFeatures = try model.prediction(from: input)
let result = BostonPricerOutput(price: outFeatures.featureValue(for: "price")!.doubleValue)
return result
}
func prediction(crime: Double, rooms: Double) throws -> BostonPricerOutput {
let input_ = BostonPricerInput(crime: crime, rooms: rooms)
return try self.prediction(input: input_)
}
}
BostonPricer is an NSObject subclass whose job is to provide an interface to a MLModel. It has two methods of interest here, both of which predict our dependent variable (pricing) from some input. The first method takes an instance of BostonPricerInput prediction(input:). This is another class that Core ML generated for us. As mentioned above, we won’t be working with this type in this post.
The second method takes values for both of our independent variables: prediction(crime:rooms:). We’ll be using this second one to generate predictions. Let’s see how this works.
BostonPricerLet’s use BostonPricer to generate predictions of housing prices based upon crime rates and the number of rooms in a house. To work with your model in code, you will need to create an instance of it. Our example here adds the model as a property on our sole UIViewController: let model = BostonPricer().
(The following few code snippets all lie within our ViewController.swift file.)
When our picker is set, we select some arbitrary rows that can be used to identify some inputs for our prediction.
@IBOutlet var picker: UIPickerView! {
didSet {
picker.selectRow(4, inComponent: Predictor.crime.rawValue, animated: false)
picker.selectRow(3, inComponent: Predictor.rooms.rawValue, animated: false)
}
}
We also call a generatePrediction() method in viewDidLoad() to ensure that our label displays a prediction that matches the picker’s selections upon launch.
override func viewDidLoad() {
super.viewDidLoad()
generatePrediction()
}
With this set up complete, we can generate a prediction whenever our UIPickerView updates its selection. There are two methods that are central to our prediction process.
func pickerView(_ pickerView: UIPickerView, didSelectRow row: Int, inComponent component: Int) {
generatePrediction()
}
fileprivate func generatePrediction() {
let selectedCrimeRow = picker.selectedRow(inComponent: Predictor.crime.rawValue)
guard let crime = crimeDataSource.value(for: selectedCrimeRow) else {
return
}
let selectedRoomRow = picker.selectedRow(inComponent: Predictor.rooms.rawValue)
guard let rooms = roomsDataSource.value(for: selectedRoomRow) else {
return
}
guard let modelOutput = try? model.prediction(crime: crime, rooms: rooms) else {
fatalError("Something went wrong with generating the model output.")
}
// Estimated price is in $1k increments (Data is from 1970s...)
priceLabel.text = priceFormatter.string(for: modelOutput.price)
}
The first method in the code above is pickerView(_:didSelectRow:inComponent:), which is defined in the UIPickerViewDelegate protocol. We use this method to track new selections on our UIPickerView. These changes will trigger a call into our model to generate a new prediction from the newly selected values.
The second method is generatePrection(), which holds all of the logic to generate a prediction from our .mlmodel. Abstracting this logic into its own method makes it easier to update the label with a new prediction when the UIViewController’s viewDidLoad() method is called. As we saw above, this allows us to call generatePrediction() from within viewDidLoad().
generatePrediction() uses the picker’s state to determine the currently selected rows in each component. We use this information to ask our crimeDataSource and roomsDataSource for the values associated with these rows. For example, the crime rate associated with row index 3 is 0.03. Likewise, the number of rooms associated with row index 3 is 3.
We pass these values to our model to generate a prediction. The code that does our work there is try? model.prediction(crime: crime, rooms: rooms).
Note that we take a small shortcut here by using try? to convert the result into an optional to avoid the error should one arise. We could be a little better about error handling in this method, but that’s not the focus of this post. It’s also not so much of a problem in our case here because our model expects Doubles. The compiler will catch any mismatching types that we may pass in as arguments to the prediction(crime:rooms:) method. This method could theoretically throw, for example, if it were expecting an image, but we passed to it an image in an unexpected format.
For our current purposes, it’s sufficient for generating a prediction from our given inputs.
After we generate our prediction, we update the priceLabel’s text property with a well-formatted version of the price.
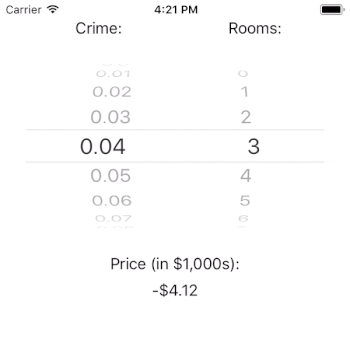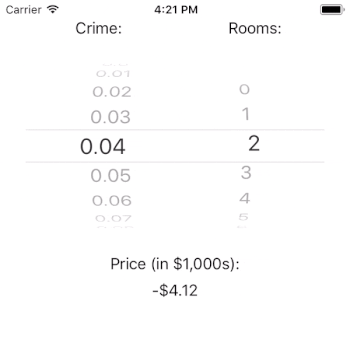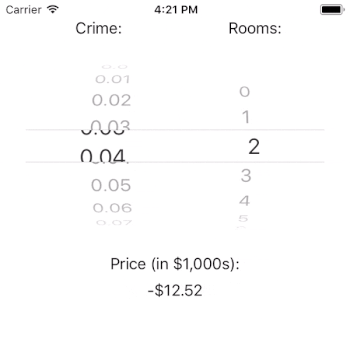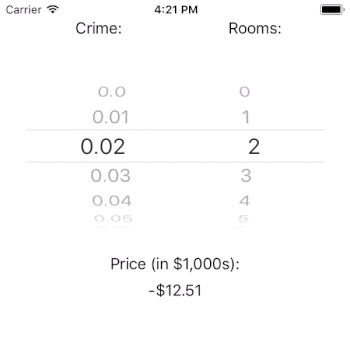
You may wonder why it is that the price can be predicted as negative. The answer lies in the important, but out of scope, work of model fit. The crux of the issue is that our model estimates that intercept to be very negative. This suggests that our model is underspecified in that it does not contain all of the independent variables that it needs to predict the outcome well. If we needed this model to perform well, we’d have to dig in here and figure out what is going on (or, we could just read Harrison and Rubinfeld’s paper).
Interestingly, it doesn’t look like crime rate has a large impact on the price of a home (given our model). That result could be a real finding, or it could be a flaw with our model. If this were a real app, it would certainly merit further investigation. Note, however, that the number of rooms has a tremendous impact on the estimated price of a house. This is just as we would expect.
This post walked through the process of using Core ML in an iOS app. With Core ML, we can take advantage of models that we have created in other tools directly within our apps. Core ML makes working with machine learning and statistical models more convenient and idiomatic.
Nonetheless, it is worth ending with a caveat. Statistics and machine learning are not simply APIs. They are entire fields of study that are equal parts art and science. Developing and selecting an informative model requires practice and study. Our app demonstrates this point pretty well: clearly there is something lacking in our model for predicting housing prices.
Core ML would likely be best leveraged by pairing a data scientist with an app team consisting of a mix of designers and developers. The data scientist would work on and tune the model to ensure that it delivers the best results. The app team would work on incorporating this model into the app to make sure that using it is a good experience that delivers value.
Yet some problems are more well-defined, and are matched with models that are already well-tested. These can be more easily “plugged into” your apps since you do not have to develop the model yourself. Examples of this include many classification problems: a) face detection, b) recognizing certain images, c) handwriting recognition, etc.
The tricky part with this approach will be making sure that the model you’ve selected is working well in your specialized case. This will involve some testing to make sure that the predictions the model is vending match what you expect. While it seems unlikely that Core ML will be able to make all modeling “plug and play”, it certainly does succeed in making it more accessible to app developers.
Learn more about why you should update your apps for iOS 11 before launch day, or download our ebook for a deeper look into how the changes affect your business.
Our introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.

The Combine framework in Swift is a powerful declarative API for the asynchronous processing of values over time. It takes full advantage of Swift...

SwiftUI has changed a great many things about how developers create applications for iOS, and not just in the way we lay out our...