
Swift Regex Deep Dive
iOS MacOur introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.
Over the past several years the barrier to entry for adopting machine learning and computer vision-related features has dropped substantially. Still, many developers are intimidated, or just don’t know where to start to take advantage of these state-of-the-art technologies. In this blog post, you will learn what computer vision is. You will then dive into how to use CreateML to train a model. Finally, you will take a look at how to use the model you created with the CoreML and Vision frameworks.
Computer vision in its simplest terms is the ability to give a machine an image and the machine to give back meaningful information about the contents of the image. There are two ways computer vision is mostly used today. The first is image classification. This is where a machine can identify what an image is as a whole, but has no concept of what part of the image contains the detected items. The other type is object detection. While similar to image classification object detection is able to find individual items in an image and report their locations within the image. This can be further built upon to perform object tracking and is widely used in fields like self-driving cars and Snap filters.
The first step in any machine learning field is training a model to teach the computer what it should look for. For the purposes of experimenting with your first ML project, Google Images combined with a bulk image downloader like Fatkun Batch Image Downloader can be a great resource.
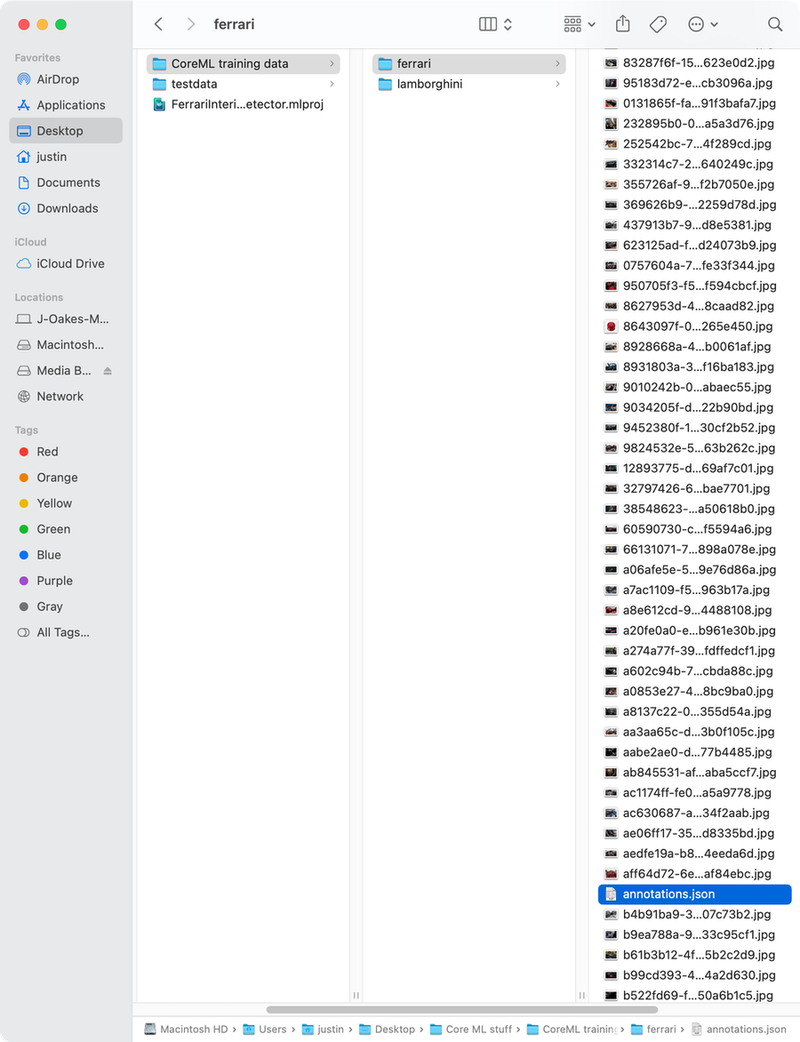
You will need at minimum 50 images for each kind of item you would like to identify, but your results will be better with more. A test data set while not strictly required will also go a long way towards helping validate your model works as it should. Make sure you have your training data organized in folders like in the screenshot below. You will need at least 2 different categories of images for image classification.
If you’re creating an object detection model you will need to include an annotations.json file in each directory that has training or testing images. This file lists the different objects that can be found in each image as well as their location in the image. Creating this file is something you can do by hand, but given your data set requires at least 50 images this can be extremely time-consuming. While it is frustrating that Apple leaves us to come up with our own way to do all this data entry, This HackerNoon article How to Label Data — Create ML for Object Detection, walks you through generating an annotations file using IBM Cloud. This does a lot to make the process less painful. Once you have your data set up you can move on to training your model.
With your data collected and organized all you need to do to create a working .mlmodel file is
This phase may take several hours to complete. As training continues you should see a graph on the screen trend towards 0. This indicates that the computer is getting better at recognizing the images provided.
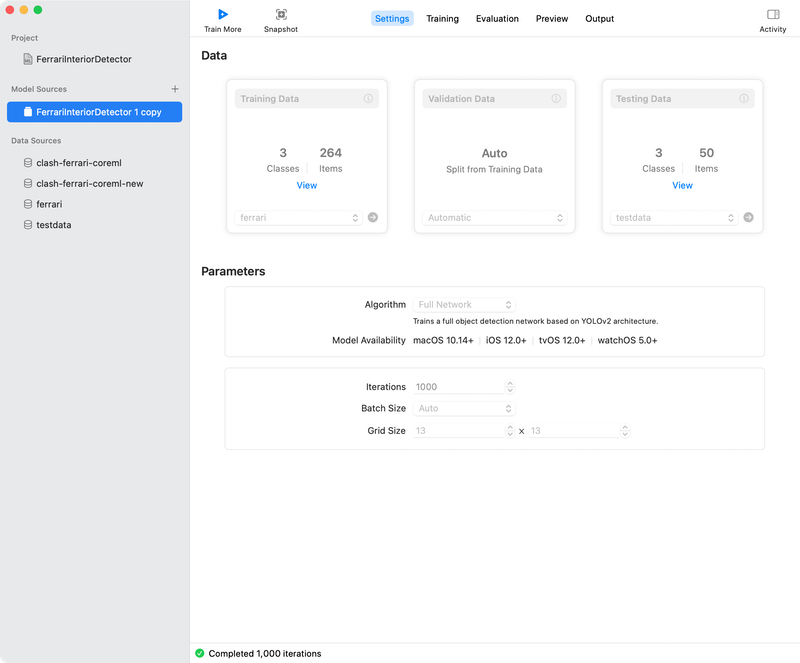
When the training completes you will have access to the Preview and Output tabs of CreateML. The Preview tab will allow you to manually drag and drop photos for you to validate your newly created model. While doing this isn’t strictly necessary it is a good way to quickly test your model before moving on. If making use of this tab for additional testing you should make sure you are feeding it new images that are not included in either the training or test data sets.
When you are comfortable that the model is good enough to move to the next stage of your project you will use the Output tab to export your work to a .mlmodel file.
Now that you have a model it is time to explore how to actually process images and get data back about them. Luckily the Vision framework has all the functionality you will need to execute queries against the model. The images you use can come directly from the camera using an AVCaptureSession or come from anywhere else in the form of a CGImage. At this point processing, an image will be pretty straightforward. Let’s take a look at the code below
// 1. Converting CMSampleBuffer from a capture session preview into a CVPixelBuffer
guard let pixelBuffer: CVPixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return }
// 2. Where we bring in the model that powers all the heavy lifting in CoreML
// All of the code to initialize the model should be automatically generated when you import the mlmodel file into the project.
guard let model = try? VNCoreMLModel(for: FerrariObjectDetector(configuration: MLModelConfiguration()).model) else { return }
let request = VNCoreMLRequest(model: model, completionHandler: requestCompletionHandler)
// 3. Where the magic happens. Passes the buffer we want Vision to analyze and the request we want to Vision to perform on it.
try? VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:])
.perform([request])
This is all you need to have Vision return objects recognized in an image. One interesting thing to note is VNImageRequestHandler can handle multiple requests on the same image at a time. The completion handler in this case is defined outside of this block of code to make reading it easier. Let’s look at it now to get an idea of what we can do with this framework and what some of the sticking points might be.
A VNRequestCompletionHandler is really just a closure that takes VNRequest and an optional error as perimeters and returns void. (VNRequest, Error?) -> Void. The completion handler in the example looks like this.
{ completedRequest, error in
guard error == nil,
// 1. Keep an eye on what type you expect your results to cast to
let results = completedRequest.results as? [VNRecognizedObjectObservation] else { return }
// 2. You may want to do more filtering here.
// ie check for overlap, or changes in objects since the last frame.
if !results.isEmpty {
// Remember we are running on the video queue
// switch back to main for updating UI
DispatchQueue.main.async {
self.handleResults(for: results)
}
} else {
DispatchQueue.main.async {
self.clearResults()
}
}
}
An easy gotcha is that the results you get back will depend on the type of model you send to your VNCoreMLRequest. Make sure if using an image classification model to cast to a [VNClassificationObservation]. In this case we’re using [VNRecognizedObjectObservation] because we’re using an object detection model. Once you do have your collection of recognized objects there are 2 properties that you will mostly be concerned with. The first will be .labels and in the case of object detection .boundingBox. The labels array contains each item the machine thinks a detected item might be. These labels are ranked by its confidence in that classification. In most cases you will want the first item in the array. You can get the actual title string and confidence using the identifier and confidence properties on the label.
The bounding box is returned as a CGRect. It is important to note that Vision uses a different coordinate system that UIView/CGLayer and will need to be converted from a bottom left to top right system to correctly make an overlay for the object. While that falls outside of the scope of this blog post getting these coordinates to true up should be easy enough with a little effort.
In this post, you learned what computer vision is, where to get training data, and how to train a model with that data using CreateML. You then learned how to use the exported model. With this in mind, you should have everything you need to start experimenting with your first computer vision project on Apple devices. For more information feel free to check out Apple’s own documentation Recognizing Objects in Live Capture and an example project Understanding a Dice Roll with Vision and Object Detection. Now go out there and get started!
Our introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.

The Combine framework in Swift is a powerful declarative API for the asynchronous processing of values over time. It takes full advantage of Swift...

SwiftUI has changed a great many things about how developers create applications for iOS, and not just in the way we lay out our...