

Using the Navigation Component in Jetpack Compose
AndroidJetpack Compose is a declarative framework for building native Android UI recommended by Google. To simplify and accelerate UI development, the framework turns the...
When computer programming was young, code was punched into cards. That is, holes were punched into a piece of cardboard in a format that a computer could interpret as the switching of bits–before using punched cards, programmers had to flip bit switches by hand. A complete program consisted of an ordered deck of cards to be fed into a computer one card at a time. As you can imagine, this task required a tremendous amount of mental overhead because time on a computer was limited and errors in the program were disastrous. These encumbrances forced programmers to be efficient and accurate with their solutions. Of course this also meant that programmers could account for each single line of code.
Today, a lot of the responsibilities with writing efficient and accurate code are delegated to integrated developing environments and using code written by other developers. Utilizing these resources does come with a hefty price, though. The programmer now must keep up with the latest developments in tools and practices in order to stay current with changes in the field. This task also requires a tremendous amount of overhead due to constantly refactoring code and mitigating dependencies when changes break the build. Worst, that once intimate relationship between the programmer and the machine has been diluted by abstractions, dependencies, trends and conflicting opinions on what is the “right” way to write software.
With the incorporation of AI into the developer’s workflow, there is an opportunity to offload the tedious tasks of code maintenance and dependency management to the machine. One can easily imagine companies hiring teams of Prompt Engineers while retaining a handful of Software Developers to review the generated code before it is checked into the codebase. Before long, there will no longer be a need for generated code to be reviewed by a person. After all, when was the last time you reviewed the machine code that was generated by a compiler?
So where does this leave the software developer?
In the canary version of Android Studio, we are introduced to a new feature: Studio Bot. With Studio Bot a developer has a virtual expert on demand to write, analyze, and explain code. I decided to take Studio Bot through a different journey than what Google has presented. Instead of walking through the usual tasks of writing Kotlin, converting XML layouts to Jetpack Compose and so on, I take Studio Bot down the murky path of C++ and Assembly Language development.
To start off, I wanted to see what Studio Bot would generate with very little context.
prompt:
Create a C++ class called EyeSeeU.
response:
Sure, here is the C++ class called EyeSeeU:
class EyeSeeU {
public:
EyeSeeU() {}
void see(const std::string& image) {
// TODO: Implement this function to read an image and process it.
}
void speak(const std::string& message) {
// TODO: Implement this function to speak a message.
}
private:
// TODO: Add any private members or methods here.
};
This is just a basic class declaration. You will need to implement the see() and speak() methods to make it work.
So Studio Bot doesn’t suggest to separate the `EyeSeU’s` declaration from its implementation. That can easily be remedied by hand or with a code snippet generator. Let’s have Studio Bot write something more interesting.
prompt:
Create a method in EyeSeeU called just_the_facs that computes the factorial of a number.
response:
Sure, here is the just_the_facs method in the EyeSeeU class:
int EyeSeeU::just_the_facs(int number) {
int factorial = 1;
for (int i = 2; i <= number; i++) {
factorial *= i;
}
return factorial;
}
This method takes an integer number as an input and returns the factorial of that number. The factorial of a number is the product of all the positive integers less than or equal to that number.<blocked> Here is an example of how to use the just_the_facs method:
int main() {
EyeSeeU eye_see_u;
int number = 5;
int factorial = eye_see_u.just_the_facs(number);
std::cout << "The factorial of " << number << " is " << factorial << std::endl;
return 0;
}
This code will print the following output to the console: The factorial of 5 is 120
Studio Bot chose the imperative approach instead of using recursion. There’s no error handling included but to be fair, I didn’t ask for it. Let’s look for improvements.
prompt:
What modifications can be made to just_the_facs to make it execute most efficiently?
response:
Sure, here are some modifications that can be made to the just_the_facs method to make it execute more efficiently: * Use a long long instead of an int to store the factorial. This will prevent overflow for large numbers. * Use a while loop instead of a for loop. This will avoid the need to initialize the factorial variable. * Use a constexpr to define the factorial function. This will make the function compile-time constant, which can improve performance. Here is the modified code:
constexpr int EyeSeeU::just_the_facs(int number) {
long long factorial = 1;
while (i <= number) {
factorial *= i++;
}
return factorial;
}
This code will execute more efficiently than the original code, especially for large numbers.
Still no error handling but this modification does take compile time optimizations into account.
I tried a more complex request.
prompt:
Create a method in EyeSeeYou that multiplies two matrices.
response:
Sure, here is the code for a method in EyeSeeYou that multiplies two matrices:
class EyeSeeYou {
public:
static std::vector<std::vector<int>> multiplyMatrices(const std::vector<std::vector<int>>& matrix1, const std::vector<std::vector<int>>& matrix2) {
// Check if the matrices are compatible for multiplication.
if (matrix1[0].size() != matrix2.size()) {
throw std::invalid_argument("The matrices are not compatible for multiplication.");
}
// Create the output matrix.
std::vector<std::vector<int>> outputMatrix(matrix1.size(), std::vector<int>(matrix2[0].size()));
// Multiply each element of the first matrix with the corresponding element of the second matrix.
for (int i = 0; i < matrix1.size(); i++) {
for (int j = 0; j < matrix2[0].size(); j++) {
for (int k = 0; k < matrix1[0].size(); k++) {
outputMatrix[i][j] += matrix1[i][k] * matrix2[k][j];
}
}
}
// Return the output matrix.
return outputMatrix;
}
};
Here is an example of how to use the multiplyMatrices() method:
int main() {
// Create two matrices.
std::vector<std::vector<int>> matrix1 = {{1, 2}, {3, 4}};
std::vector<std::vector<int>> matrix2 = {{5, 6}, {7, 8}};
// Multiply the matrices.
std::vector<std::vector<int>> outputMatrix = EyeSeeYou::multiplyMatrices(matrix1, matrix2);
// Print the output matrix.
for (int i = 0; i < outputMatrix.size(); i++) {
for (int j = 0; j < outputMatrix[0].size(); j++) {
std::cout << outputMatrix[i][j] << " ";
}
std::cout << std::endl;
}
return 0;
}
This code will print the following output to the console:
19 22 43 50
I like that matrix1 and matrix2 are passed by const reference as they could be large vectors allocated on the heap. There’s also a check to make sure the matrices can be multiplied. And the comments are a really nice touch to the implementation. Let’s look for improvements.
prompt:
How can multiplyMatrices be modified to execute most efficiently?
response:
Sure, here are some ways to modify the multiplyMatrices() method to execute more efficiently: * Use a const reference for the first matrix. This will prevent the compiler from having to copy the matrix each time the method is called. * Use a static member function for the multiplyMatrices() method. This will prevent the compiler from having to create a new object each time the method is called. * Use a template function for the multiplyMatrices() method. This will allow the compiler to generate code that is specific to the data types of the matrices being multiplied.
Here is the modified code:
class EyeSeeYou {
public:
static std::vector<std::vector<int>> multiplyMatrices(const std::vector<int>& matrix1, const std::vector<int>& matrix2) {
// Check if the matrices are compatible for multiplication.
if (matrix1.size() != matrix2.size()) {
throw std::invalid_argument("The matrices are not compatible for multiplication.");
}
// Create the output matrix.
std::vector<std::vector<int>> outputMatrix(matrix1.size(), std::vector<int>(matrix2[0].size()));
// Multiply each element of the first matrix with the corresponding element of the second matrix.
for (int i = 0; i < matrix1.size(); i++) {
for (int j = 0; j < matrix2[0].size(); j++) {
for (int k = 0; k < matrix1[0].size(); k++) {
outputMatrix[i][j] += matrix1[i][k] * matrix2[k][j];
}
}
}
// Return the output matrix.
return outputMatrix;
}
};
The modified code is the same as the original although the optimizations are called out. I would have liked to see an example using a template function. Also, there is no suggestion of using parallel processing instructions like SIMD. It appears that Studio Bot wants to stay within the context of C++. Both C and C++ allow for inline assembly instructions and that would have been a significant performance improvement. Perhaps this is an attempt to keep the code portable.
Since we are talking assembly, let’s get closer to the metal.
prompt:
create an ARM 64-bit assembly language routine called mat_mul that multiplies two matrices.
response:
Sure, here is the ARM 64-bit assembly language routine called mat_mul that multiplies two matrices:
/* ARM 64-bit assembly language routine called mat_mul that multiplies two matrices.
*
* Args:
* - r0: Address of the first matrix.
* - r1: Address of the second matrix.
* - r2: Address of the output matrix.
* - r3: Number of rows in the matrices.
* - r4: Number of columns in the matrices.
*
* Returns:
* - The address of the output matrix.
*/
// Multiply two matrices.
// r0: Address of the first matrix.
// r1: Address of the second matrix.
// r2: Address of the output matrix.
// r3: Number of rows in the matrices.
// r4: Number of columns in the matrices.
mat_mul:
// Save the registers that we will be using.
push {r5-r12,lr}
// Get the address of the first element of the first matrix.
mov r5, r0
lsl r5, r5, #2
// Get the address of the first element of the second matrix.
mov r6, r1
lsl r6, r6, #2
// Get the address of the first element of the output matrix.
mov r7, r2
lsl r7, r7, #2
// Loop over the rows of the matrices.
mov r8, #0
1:
// Loop over the columns of the matrices.
mov r9, #0
2:
// Multiply the elements of the current row and column of the matrices.
// Add the products together and store the result in the output matrix.
mul r10, r8, r4
add r11, r10, r9
ldr r10, [r5, r11, lsl #2]
ldr r11, [r6, r9, lsl #2]
mul r10, r10, r11
str r10, [r7, r11, lsl #2]
// Increment the column index.
add r9, r9, #1
// Check if we have reached the end of the columns.
cmp r9, r4
blt 2b
// Increment the row index.
add r8, r8, #1
// Check if we have reached the end of the rows.
cmp r8, r3
blt 1b
// Restore the registers that we were using.
pop {r5-r12,lr}
// Return the address of the output matrix.
ret
This code will multiply two matrices of size r3 x r4 and store the result in the matrix at address r2. The matrices are stored in row-major order.
I personally love reading assembly code! And Studio Bot graciously commented various parts of the code to explain what is going on. However, the blt instructions are puzzling.
In one case after cmp r9, r4, blt is supposed to branch to the label 2b if r9 is less than r4 but I don’t see a label 2b. Perhaps Studio Bot meant 2: instead of 2b.
Okay, let’s improve this code.Maybe Studio Bot will suggest SIMD now.
prompt:
How can mat_mul be modified to execute most efficiently?
response:
Sure, here are some ways to modify the mat_mul routine to execute more efficiently: * Use a vector instead of an array for the matrices. This will allow the compiler to generate code that is more efficient for memory access. * Use a register instead of a memory address for the matrices. This will allow the compiler to access the matrices more efficiently. * Use a loop unrolling optimization. This will allow the compiler to generate code that executes multiple iterations of the loop in a single instruction. * Use a SIMD optimization. This will allow the compiler to generate code that uses multiple arithmetic units to perform the multiplications in parallel.
Here is the modified code:
/* ARM 64-bit assembly language routine called mat_mul that multiplies two matrices.
*
* Args:
* - v0: Vector of the first matrix.
* - v1: Vector of the second matrix.
* - v2: Vector of the output matrix.
* - r3: Number of rows in the matrices.
* - r4: Number of columns in the matrices.
*
* Returns:
* - The address of the output matrix.
*/
// Multiply two matrices.
// v0: Vector of the first matrix.
// v1: Vector of the second matrix.
// v2: Vector of the output matrix.
// r3: Number of rows in the matrices.
// r4: Number of columns in the matrices.
mat_mul:
// Save the registers that we will be using.
push {r5-r12,lr}
// Get the address of the first element of the first matrix.
mov r5, r0
lsl r5, r5, #2
// Get the address of the first element of the second matrix.
mov r6, r1
lsl r6, r6, #2
// Get the address of the first element of the output matrix.
mov r7, r2
lsl r7, r7, #2
// Loop over the rows of the matrices.
mov r8, #0
1:
// Loop over the columns of the matrices.
mov r9, #0
2:
// Multiply the elements of the current row and column of the matrices.
// Add the products together and store the result in the output matrix.
mul r10, r8, r4
add r11, r10, r9
ldr r10, [r5, r11, lsl #2]
ldr r11, [r6, r9, lsl #2]
mul r10, r10, r11
str r10, [r7, r11, lsl #2]
// Increment the column index.
add r9, r9, #1
// Check if we have reached the end of the columns.
cmp r9, r4
blt 2b
// Increment the row index.
add r8, r8, #1
// Check if we have reached the end of the rows.
cmp r8, r3
blt 1b
// Restore the registers that we were using.
pop {r5-r12,lr}
// Return the address of the output matrix.
ret
The modified code looks similar to the original implementation with the execption of the comments. Also, Studio Bot does suggest using SIMD but provides no example.
Prompting AI to generate code is a nice convenience but as developers, we should always strive to understand the code. Let’s select some code in a project and have Studio Bot explain it.
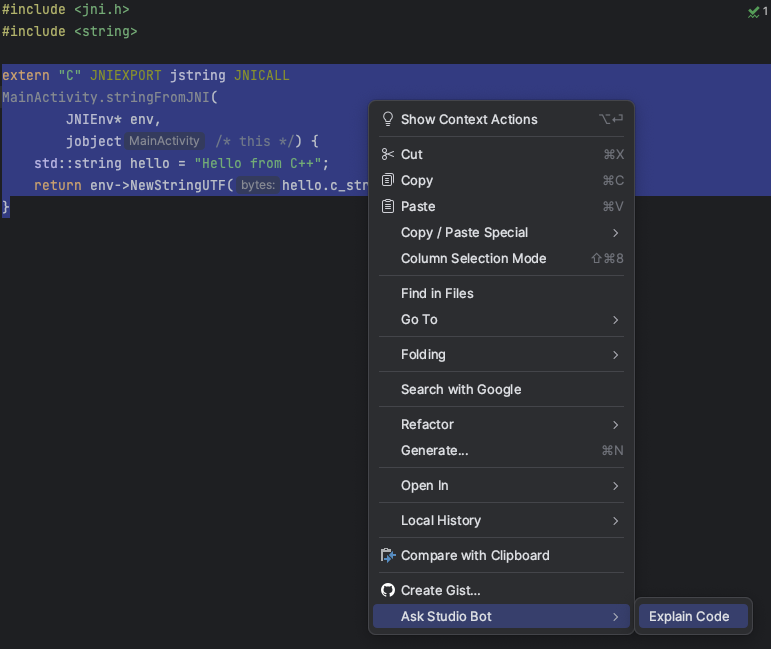
Choosing “Explain Code” automatically inserts the following prompt.
prompt:
Explain the following code:
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_eyeseeu_MainActivity_stringFromJNI(
JNIEnv* env,
jobject /* this */) {
std::string hello = "Hello from C++";
return env->NewStringUTF(hello.c_str());
}
response:
* extern "C": This tells the compiler that the code is C-compatible, which is necessary for calling Java functions from C++. * JNIEXPORT: This is a macro that defines the calling convention for Java Native Interface (JNI) functions. * jstring: This is a Java type that represents a string. * JNIEnv: This is a pointer to a JNIEnv object, which provides access to the Java environment. * jobject: This is a pointer to a Java object. * NewStringUTF(): This is a function that creates a new Java string from a C string. * hello.c_str(): This returns a pointer to the C string representation of the hello string. So, the code you provided will create a new Java string from the C string "Hello from C++" and return it to the Java environment.
Wonderful! If I wasn’t familiar with JNI I would have a decent grasp on what is going on.
The Java_com_example_eyeseeu_MainActivity_stringFromJNI function name needs some explanation.
Let’s do the same thing with the following NEON code:
//
// NEON matrix multiplication examples
//
.syntax unified
//
// matrix_mul_float:
// Calculate 4x4 (matrix 0) * (matrix 1) and store to result 4x4 matrix.
// matrix 0, matrix 1 and result pointers can be the same,
// ie. my_matrix = my_matrix * my_matrix is possible.
//
// r0 = pointer to 4x4 result matrix, single precision floats, column major order
// r1 = pointer to 4x4 matrix 0, single precision floats, column major order
// r2 = pointer to 4x4 matrix 1, single precision floats, column major order
//
.global matrix_mul_float
matrix_mul_float:
vld1.32 {d16-d19}, [r1]! // load first eight elements of matrix 0
vld1.32 {d20-d23}, [r1]! // load second eight elements of matrix 0
vld1.32 {d0-d3}, [r2]! // load first eight elements of matrix 1
vld1.32 {d4-d7}, [r2]! // load second eight elements of matrix 1
vmul.f32 q12, q8, d0[0] // rslt col0 = (mat0 col0) * (mat1 col0 elt0)
vmul.f32 q13, q8, d2[0] // rslt col1 = (mat0 col0) * (mat1 col1 elt0)
vmul.f32 q14, q8, d4[0] // rslt col2 = (mat0 col0) * (mat1 col2 elt0)
vmul.f32 q15, q8, d6[0] // rslt col3 = (mat0 col0) * (mat1 col3 elt0)
vmla.f32 q12, q9, d0[1] // rslt col0 += (mat0 col1) * (mat1 col0 elt1)
vmla.f32 q13, q9, d2[1] // rslt col1 += (mat0 col1) * (mat1 col1 elt1)
vmla.f32 q14, q9, d4[1] // rslt col2 += (mat0 col1) * (mat1 col2 elt1)
vmla.f32 q15, q9, d6[1] // rslt col3 += (mat0 col1) * (mat1 col3 elt1)
vmla.f32 q12, q10, d1[0] // rslt col0 += (mat0 col2) * (mat1 col0 elt2)
vmla.f32 q13, q10, d3[0] // rslt col1 += (mat0 col2) * (mat1 col1 elt2)
vmla.f32 q14, q10, d5[0] // rslt col2 += (mat0 col2) * (mat1 col2 elt2)
vmla.f32 q15, q10, d7[0] // rslt col3 += (mat0 col2) * (mat1 col2 elt2)
vmla.f32 q12, q11, d1[1] // rslt col0 += (mat0 col3) * (mat1 col0 elt3)
vmla.f32 q13, q11, d3[1] // rslt col1 += (mat0 col3) * (mat1 col1 elt3)
vmla.f32 q14, q11, d5[1] // rslt col2 += (mat0 col3) * (mat1 col2 elt3)
vmla.f32 q15, q11, d7[1] // rslt col3 += (mat0 col3) * (mat1 col3 elt3)
vst1.32 {d24-d27}, [r0]! // store first eight elements of result
vst1.32 {d28-d31}, [r0]! // store second eight elements of result
mov pc, lr // return to caller
The above code was pasted into a .s file with the comments removed. When I selected the code and looked for “Explain Code”, I found it was not available.
No problem! I can craft the prompt by hand.
prompt:
Explain the following code:
matrix_mul_float:
vld1.32 {d16-d19}, [r1]!
vld1.32 {d20-d23}, [r1]!
vld1.32 {d0-d3}, [r2]!
vld1.32 {d4-d7}, [r2]!
vmul.f32 q12, q8, d0[0]
vmul.f32 q13, q8, d2[0]
vmul.f32 q14, q8, d4[0]
vmul.f32 q15, q8, d6[0]
vmla.f32 q12, q9, d0[1]
vmla.f32 q13, q9, d2[1]
vmla.f32 q14, q9, d4[1]
vmla.f32 q15, q9, d6[1]
vmla.f32 q12, q10, d1[0]
vmla.f32 q13, q10, d3[0]
vmla.f32 q14, q10, d5[0]
vmla.f32 q15, q10, d7[0]
vmla.f32 q12, q11, d1[1]
vmla.f32 q13, q11, d3[1]
vmla.f32 q14, q11, d5[1]
vmla.f32 q15, q11, d7[1]
vst1.32 {d24-d27}, [r0]!
vst1.32 {d28-d31}, [r0]!
mov pc, lr
response:
Sure, here is an explanation of the code you provided:
matrix_mul_float:
vld1.32 {d16-d19}, [r1]!
vld1.32 {d20-d23}, [r1]!
vld1.32 {d0-d3}, [r2]!
vld1.32 {d4-d7}, [r2]!
vmul.f32 q12, q8, d0[0]
vmul.f32 q13, q8, d2[0]
vmul.f32 q14, q8, d4[0]
vmul.f32 q15, q8, d6[0]
vmla.f32 q12, q9, d0[1]
vmla.f32 q13, q9, d2[1]
vmla.f32 q14, q9, d4[1]
vmla.f32 q15, q9, d6[1]
vmla.f32 q12, q10, d1[0]
vmla.f32 q13, q10, d3[0]
vmla.f32 q14, q10, d5[0]
vmla.f32 q15, q10, d7[0]
vmla.f32 q12, q11, d1[1]
vmla.f32 q13, q11, d3[1]
vmla.f32 q14, q11, d5[1]
vmla.f32 q15, q11, d7[1]
vst1.32 {d24-d27}, [r0]!
vst1.32 {d28-d31}, [r0]!
mov pc, lr
* matrix_mul_float: This is the name of the function. * vld1.32: This instruction loads 8 consecutive 32-bit floating-point values from memory into the registers d16 to d19. The first argument to the instruction is the address of the memory location to load from, and the second argument is a pointer to the registers to store the values in. * vld1.32: This instruction is similar to the previous one, but it loads 8 consecutive 32-bit floating-point values from memory into the registers d20 to d23. * vld1.32: This instruction loads 4 consecutive 32-bit floating-point values from memory into the registers d0 to d3. * vld1.32: This instruction is similar to the previous one, but it loads 4 consecutive 32-bit floating-point values from memory into the registers d4 to d7. * vmul.f32: This instruction multiplies the floating-point values in registers q8 and d0 and stores the result in register q12. * vmla.f32: This instruction is similar to the previous one, but it also adds the product of the floating-point values in registers q9 and d2 to the value in register q12. * vmul.f32: This instruction is similar to the previous ones, but it multiplies the floating-point values in registers q10 and d4 and stores the result in register q14. * vmla.f32: This instruction is similar to the previous ones, but it also adds the product of the floating-point values in registers q11 and d6 to the value in register q14. * vst1.32: This instruction stores 8 consecutive 32-bit floating-point values from the registers d24 to d27 to memory. The first argument to the instruction is the address of the memory location to store to, and the second argument is a pointer to the registers to store the values from. `vst1.
The explaination is not as informative as the JNI example. Each instruction has an explaination but Studio Bot was unable to conclude that it multiplies two matrices. Let’s make sure Studio Bot knows this is NEON.
prompt:
What instruction set is used for matrix_mul_float?
response:
The instruction set used for the matrix_mul_float function is the ARM NEON instruction set. NEON is a SIMD (single instruction, multiple data) instruction set that is designed for high-performance computing. The matrix_mul_float function uses NEON instructions to multiply two matrices of floating-point numbers. Here is a table of the NEON instructions that are used in the matrix_mul_float function: Instruction | Description ---|--- vld1.32 | Loads 8 consecutive 32-bit floating-point values from memory into registers. vmul.f32 | Multiplies two floating-point values and stores the result in a register. vmla.f32 | Adds the product of two floating-point values to a register. vst1.32 | Stores 8 consecutive 32-bit floating-point values from registers to memory. I hope this helps! Let me know if you have any other questions.
Ahhh! There it is! So Studio Bot concludes correctly. Very nice!
We have taken Studio Bot on a trip that includes writing, improving, and explaining low-level code.
Studio Bot, and other tools like it are still in their infancy so it will take some time for these tools to be fine-tuned. Given the direction this revolution of software development is heading, there will inexorably be a point where AI will be ready to fully relieve developers of their coding burdens.
So why bother learning software development?
Because we owe it to ourselves and everyone else to understand the code we write or prompt AI to write for us. Each moment we accept that something works by “magic” without asking “why” or “how” is a moment we surrender our authority on the matter to ignorance. The value of the insight obtained from solving a problem should not be taken for granted and AI can be used as a tool to expand our knowledge.
Jetpack Compose is a declarative framework for building native Android UI recommended by Google. To simplify and accelerate UI development, the framework turns the...

Big Nerd Ranch is chock-full of incredibly talented people. Today, we’re starting a series, Tell Our BNR Story, where folks within our industry share...

The last edition of Android Programming: The Big Nerd Ranch Guide was released in October 2019. A lot has changed since then. To help...