

Software Maintainability in New Technologies
Leveling UpEvery decade at the longest, the software development industry undergoes significant technological shifts, and these shifts make it difficult to keep delivering maintainable software....
Usually when I hear a conversation about Dependency Inversion, one of the SOLID principles of object-oriented design, a question comes up about its name. It’s often summarized as “depend on abstractions” and that makes sense—but why is it called dependency inversion?
This isn’t just trivia. Understanding the “inversion” in “dependency inversion” has the potential to transform your abstractions into powerful design tools.
First, a brief refresher on dependencies. Class A depends on class B if a change in B could cause a change in A. There are several reasons changes can propagate, including:
Next, let’s see an example of what it means to change a dependency on a concrete class into a dependency on an abstraction.
Say we have a blog app. We have a business logic class, CreateBlogPost, that handles all the necessary tasks for when a blog post is created. It delegates to other objects to perform detailed tasks, such as asking an instance of TwitterService to tweet about the new post:
class CreateBlogPost
# initializer, attr_accessors, etc.
def run
# create the post
# do some other steps
TwitterService.new.add_status(message, username, password)
# more steps
end
end
A CreateBlogPost instance sends a message to a TwitterService instance. There are a few different ways you can describe this relationship:
CreateBlogPost is a client of TwitterService—it makes use of functionality TwitterService provides.CreateBlogPost has an association with TwitterService.CreateBlogPost depends on TwitterService.To visualize this dependency, it’s helpful to use a class diagram, where association is represented by a V-shaped arrow from the sender to the receiver:

Ideally, we’d also like the option to post notifications to social networks other than Twitter. The core business logic around creating a blog post would be the same, so we would want to reuse CreateBlogPost instead of duplicating its code. But we can’t if it depends specifically on TwitterService. The problem stems from the fact that CreateBlogPost depends on a “concrete” class—a class with a specific implementation. Any time we get a CreateBlogPost object, we are forced to take a TwitterService too.
When we want to be able to reuse a class but our design prevents it, that’s a design problem—and it’s the problem dependency inversion solves.
To get out of this bind, let’s introduce an abstraction between the two. Let’s call it SocialMediaService for now:

Extension is represented in a class diagram with a white triangular arrow from the child to the parent. SocialMediaService is an abstraction, and TwitterService is a concrete class that implements that abstraction. Now CreateBlogPost isn’t associated to a TwitterService per se, but rather to some kind of SocialMediaService—and that’s all it knows. (Making this work in code often involves passing a SocialMediaService implementation to CreateBlogPost when it’s instantiated.)
Take a look at the direction of the arrows. The arrow connecting to CreateBlogPost still goes left-to-right. So why does the arrow connecting to TwitterService go right-to-left? Doesn’t the flow of control go from left to right? Yes, but the arrows don’t represent the flow of control; they represent the flow of change.
CreateBlogPost and TwitterService both depend on SocialMediaService, because if the signature of a method on SocialMediaService abstraction changed, both of them might need to change. On the other hand, changes to CreateBlogPost or TwitterService won’t propagate on SocialMediaService. It is the contract through which they communicate; as long as the contract stays the same, CreateBlogPost and TwitterService can change all they want.
We’re depending on an abstraction now…but we still haven’t discovered why it’s called “inverting” the dependency. At first the dependency arrow from CreateBlogPost to TwitterService went from left to right:
After introducing our abstraction, there’s still an arrow that direction, but now there’s also an arrow from right-to-left: from TwitterService to SocialMediaService:
If we wanted to make it look more like an inversion, we could change how we draw the diagram. Let’s draw SocialMediaService close to CreateBlogPost. The longest dependency line points left, so it looks more like an inversion:

But if we draw the abstraction close to TwitterService we’re right back where we started: the longest dependency line points right!

Does this mean our diagram is totally arbitrary?
No. It’s actually a way to visualize two design alternatives: we can think about the abstraction either as more closely associated with CreateBlogPost or with TwitterService. In other words, the abstraction could either be owned by the caller or the implementor.
Our goal is to invert the dependency and make CreateBlogPost independent of TwitterService. Our diagram suggests that, to accomplish this,the caller CreateBlogPost should own the abstraction SocialMediaService. “The caller should own the abstraction” is more commonly phrased as as “the client owns the interface.” The abstraction should be in the same “package” (namespace, module, or group) as the client, not the implementor:
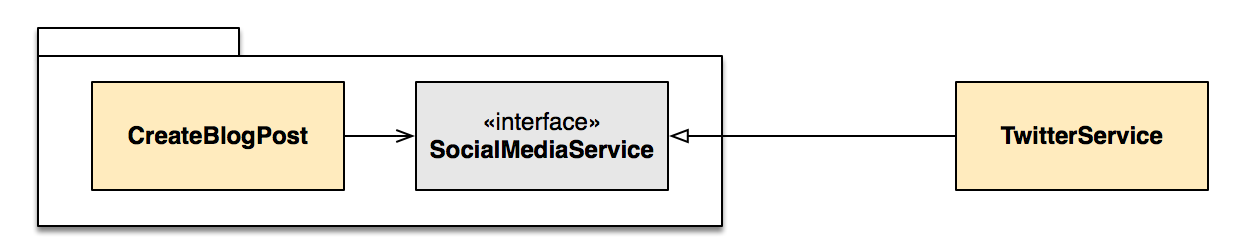
Drawing the package on the diagram makes it easier to see that the dependency has been inverted: TwitterService depends on the client package, which includes CreateBlogPost and SocialMediaService.
Just saying the client owns the abstraction doesn’t change anything: we also need to let the client define the abstraction in terms of the role it needs that abstraction to play.
Think about the abstraction’s name: SocialMediaService. CreateBlogPost doesn’t care about social media per se; what it cares about is notifying people about a new blog post. That’s the need that should drive the definition of the abstraction, leading to a name like PostNotifier, and the corresponding implementation TwitterPostNotifier:
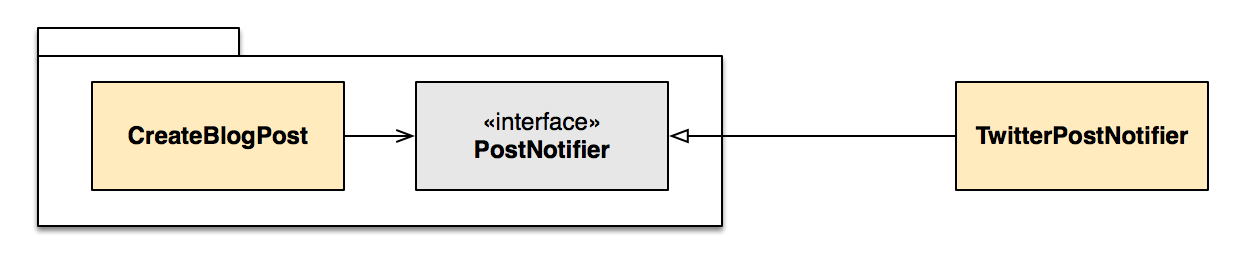
A SocialMediaService might receive a message like:
social_media_service.add_status(message, username, password)
A message like this restricts CreateBlogPost: it can only to adding statuses to social media platforms that take a message, username, and password. But a PostNotifier is more likely to receive a message like:
post_notifier.created(blog_post)
The parameter it receives is simply the newly-created blog post itself, and the PostNotifier takes care of any details about how to send a notification: what account to post it to, what the status message should say, etc. This message design makes the CreateBlogPost business logic class even more independent of the implementation details of its collaborators.
So we’ve accomplished the goal of making our business logic class more reusable. And we really have inverted the dependency! At first CreateBlogPost depended on TwitterService:
But now TwitterPostNotifier depends on the package including CreateBlogPost:
Class diagrams have helped us see that depending on abstractions doesn’t automatically invert the direction of dependencies: you need to make sure the client defines the abstraction. Doing so keeps your business logic classes from being encumbered with implementation details.
Take a look at the abstractions in your code and see if you can refactor them to focus more on the role they play for the client. And maybe even try drawing a class diagram to see if it helps!
If you’d like to know more about Dependency Inversion, take a look at the original Dependency Inversion Principle article, or the original book on the SOLID principles, Agile Software Development: Principles, Patterns, and Practices. And you can learn more about role-based design from Rebecca Wirfs-Brock and Alan McKean in Object Design: Roles, Responsibilities, and Collaborations.

Every decade at the longest, the software development industry undergoes significant technological shifts, and these shifts make it difficult to keep delivering maintainable software....

Where is the Ruby language headed? At RubyConf 2021, the presentations on the language focused on type checks and performance—where performance can be subdivided...

At RubyConf 2021, TypeProf-IDE was announced. It's a Visual Studio Code integration for Ruby’s TypeProf tool to allow real-time type analysis and developer feedback....