The post Machine Learning in iOS Using Core ML appeared first on Big Nerd Ranch.
]]>Core ML is an exciting new framework that makes running various machine learning and statistical models on macOS and iOS feel natively supported. The framework helps developers to integrate already prepared statistical and machine learning models into their apps. It builds on top of Apple’s lower-level machine learning primitives, some of which were announced at WWDC 2016.
Core ML helps you in three important ways:
- Core ML supports a wide variety of machine learning models. From neural networks to generalized linear models, Core ML is here to help.
- Core ML facilitates adding trained machine learning models into your application. This goal is achieved via
coremltools, which is a Python package designed to help generate an.mlmodelfile that Xcode can use. - Core ML automatically creates a custom programmatic interface that supplies an API to your model. This helps you to work with your model directly within Xcode, allowing you to work with it like it is a native type.
After reading this post, you will get an introduction to the life cycle of working with Core ML. You will create a model in Python, generate the .mlmodel file, add it to Xcode and use this model via Core ML to run it on a device. Let’s get started!
Predicting Home Prices
Core ML supports a wide variety of models. In supporting these models, Core ML expects us to create them in a few set environments. This helps to delimit the support domain for the coremltools package that we need to use to generate our .mlmodel file.
In this app, we will use scikit-learn to develop a linear regression model to predict home prices. scikit-learn is a Python package built on top of NumPy, SciPy, and matplotlib that is designed for general purpose data analysis. Our regression model to predict housing prices will be based upon two predictor variables.
- Crime rate
- The number of rooms in the house
An aside: our goal is not to create the most accurate model. Instead, our purpose in this post is to develop something plausible that we can showcase in an app. Model building is difficult, and this isn’t the right post for a deep dive into model selection and performance.
The model we will develop will take the following form: 𝑦 = α + β₁𝑥₁ + β₂𝑥₂ + 𝑒
Our variable y is the dependent variable we seek to predict: housing prices. x1 is an independent variable that will represent crime rates. x2 is an independent variable that represents the number of rooms in a house. e is an error term representing the disparity between the model’s prediction for a given record in the data set and its actual value. We won’t actually model this parameter, but include it in the model’s specification above for the sake of completeness.
α, β₁, and β₂ are coefficients (technically, α is called the intercept) that the model will estimate to help us generate predictions. Incidentally, it is these parameters that make our model linear. y is the result of a linear combination of the coefficients and the independent variables.
An Aside on Building an Intuition for Regression
If you don’t know what regression is, that’s okay. It is a foundational model in statistics and machine learning. The main goal of regression is to draw a line through data. In so doing, the model seeks to estimate the necessary parameters needed for line drawing.
Remember the formula y = mx + b? y is the y-coordinate, m is the slope, x is the x-coordinate, and b is the intercept. Recalling these will give you a good intuition for what regression is doing.
For example, consider this plot:
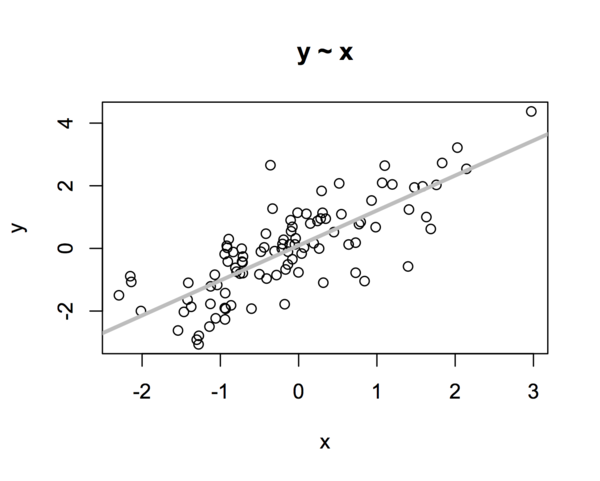
The chart shows two variables, x and y, that I generated randomly from the Normal Distribution. Each has 100 samples. x is distributed with a mean of 0, and a standard deviation of 1: x ~ N(0, 1). y is generated with a mean of x and a standard deviation of 1: y ~ N(x, 1). That is, each y is generated by drawing a sample for the Normal Distribution whose mean is x. For example, the first value for y is generated by sampling from the Normal Distribution whose mean is the first value in x.
Generating y in this way helps to make the association between the two variables.
Next, I performed a bivariate regression to estimate the intercept and slope that define the relationship between y and x. The line drawn on the chart above shows the result of that model. In this case, it’s a pretty good fit for the data, which we would expect given that y was defined as a function of x plus some random noise that came from sampling from the Normal Distribution.
So, at the risk of being somewhat reductive, regression is all about drawing lines. If you’re curious to learn more about drawing lines, take a look at our post on machine learning.
The Data: Boston Housing Data Set
The data for this post come from a study by Harrison and Rubinfeld (1978) and are open to the public. The data set comprises 506 observations on a variety of factors the authors collected to predict housing prices in the Boston area. It comes with the following predictors (the first five records):
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0
PTRATIO B LSTAT
0 15.3 396.90 4.98
1 17.8 396.90 9.14
2 17.8 392.83 4.03
3 18.7 394.63 2.94
4 18.7 396.90 5.33
The dependent variable looks like (again, the first five records):
MEDV
0 24.0
1 21.6
2 34.7
3 34.4
4 36.2
The dependent variable shows the median value of the home’s price in units of $1,000. The data are from the 1970s, and so even tacking on a few zeros to these prices is still enviably low!
With an understanding of what the data looks like, it’s time to write the regression model.
The Python Model
We define the regression model in Python 2.7. This is what coremltools needs. Here is the code that defines the model:
import coremltools
from sklearn import datasets, linear_model
import pandas as pd
from sklearn.externals import joblib
# Load data
boston = datasets.load_boston()
boston_df = pd.DataFrame(boston.data)
boston_df.columns = boston.feature_names
# Define model
X = boston_df.drop(boston_df.columns[[1,2,3,4,6,7,8,9,10,11,12]], axis=1)
Y = boston.target
lm = linear_model.LinearRegression()
lm.fit(X, Y)
# coefficients
lm.intercept_
lm.coef_
# Convert model to Core ML
coreml_model = coremltools.converters.sklearn.convert(lm, input_features=["crime", "rooms"], output_feature_names="price")
# Save Core ML Model
coreml_model.save("BostonPricer.mlmodel")
You don’t need to be very familiar with Python to be able to follow along. The top part of this file imports the necessary packages.
Next, we load the Boston housing data, and perform a little bit of clean up to make sure that our model has the dependent and independent variables it needs. With the variables in hand, we can create our linear regression model: lm = linear_model.LinearRegression(). Once we have created the model, we can fit it with our data: lm.fit(X, Y). Fitting the data will generate the coefficients we need to create predictions from new data in our app. The .mlmodel will give us access to these coefficients to make those predictions.
The last two lines of the Python code convert the linear model to the .mlmodel format and save it out to a file.
coremltools.converters.sklearn.convert(lm, ["crime", "rooms"], "price") does the conversion. coremltools provides a number of converters that you can use to convert your models to the .mlmodel format. See here for more details. Download the documentation on that page to see more information about converting.
Run python NAME_OF_FILE.py to generate the BostonPricer.mlmodel. For example, my file name is “pricer_example.py,” so I ran python pricer_example.py. Make sure to run this from within the same directory as your Python script file. Your .mlmodel file will be created in this same location.
A Small, But Learned, iOS App
Our iOS app will be a simple single view application. It will provide a pretty sparse user interface to generate predictions of housing prices based on our two independent variables. The single view will have a UIPickerView with two components, one for crime rates and one for rooms. It will also have a label to show the prices predicted from the inputs selected in the picker.
The app will look like this:
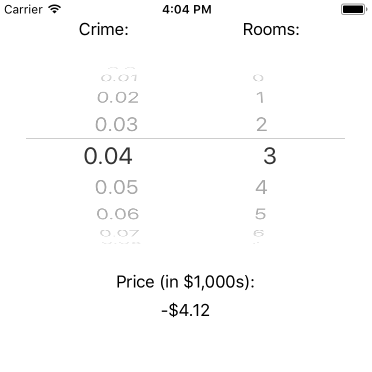
We won’t go through setting up the UI in the storyboard. Feel free to take a look at the associated Xcode project if you’re curious.
Adding BostonPricer.mlmodel to an Xcode Project
Drag and drop the .mlmodel file into your Xcode project in the usual way. For example, you can drop it into your Project Navigator. This creates a nice interface to view some details about your model from within Xcode. You can view this interface by clicking on your BostonPricer.mlmodel file in Xcode.
Adding this model file also automatically created a few generated classes named BostonPricer, BostonPricerInput and BostonPricerOutput.
BostonPricercan be used to create an instance of your model. It provides an API for you to call into it to produce predictions.BostonPricerInputis a class that you can use to create input data to pass to an instance of your model type,BostonPricer. The model will use this information to generate a prediction. You can work with this type if you like, but it isn’t necessary.BostonPriceralso provides a method to generate a prediction from the data types that match your input variables. More on this soon.BostonPricerOutputis a class that models the output of your model based upon some input. You use this generated type to work with the prediction your model produces.
The class definitions are somewhat hidden from you, but you can find them if you ‘command-click’ on BostonPricer. A pop up will appear that will give you the option to “Jump to Definition”. Select “Jump to Definition” and Xcode will take you BostonPricer’s implementation. The other generated class definitions are located in the same file. It should look like this:
@objc class BostonPricer:NSObject {
var model: MLModel
init(contentsOf url: URL) throws {
self.model = try MLModel(contentsOf: url)
}
convenience override init() {
let bundle = Bundle(for: BostonPricer.self)
let assetPath = bundle.url(forResource: "BostonPricer", withExtension:"mlmodelc")
try! self.init(contentsOf: assetPath!)
}
func prediction(input: BostonPricerInput) throws -> BostonPricerOutput {
let outFeatures = try model.prediction(from: input)
let result = BostonPricerOutput(price: outFeatures.featureValue(for: "price")!.doubleValue)
return result
}
func prediction(crime: Double, rooms: Double) throws -> BostonPricerOutput {
let input_ = BostonPricerInput(crime: crime, rooms: rooms)
return try self.prediction(input: input_)
}
}
BostonPricer is an NSObject subclass whose job is to provide an interface to a MLModel. It has two methods of interest here, both of which predict our dependent variable (pricing) from some input. The first method takes an instance of BostonPricerInput prediction(input:). This is another class that Core ML generated for us. As mentioned above, we won’t be working with this type in this post.
The second method takes values for both of our independent variables: prediction(crime:rooms:). We’ll be using this second one to generate predictions. Let’s see how this works.
Using BostonPricer
Let’s use BostonPricer to generate predictions of housing prices based upon crime rates and the number of rooms in a house. To work with your model in code, you will need to create an instance of it. Our example here adds the model as a property on our sole UIViewController: let model = BostonPricer().
(The following few code snippets all lie within our ViewController.swift file.)
When our picker is set, we select some arbitrary rows that can be used to identify some inputs for our prediction.
@IBOutlet var picker: UIPickerView! {
didSet {
picker.selectRow(4, inComponent: Predictor.crime.rawValue, animated: false)
picker.selectRow(3, inComponent: Predictor.rooms.rawValue, animated: false)
}
}
We also call a generatePrediction() method in viewDidLoad() to ensure that our label displays a prediction that matches the picker’s selections upon launch.
override func viewDidLoad() {
super.viewDidLoad()
generatePrediction()
}
With this set up complete, we can generate a prediction whenever our UIPickerView updates its selection. There are two methods that are central to our prediction process.
func pickerView(_ pickerView: UIPickerView, didSelectRow row: Int, inComponent component: Int) {
generatePrediction()
}
fileprivate func generatePrediction() {
let selectedCrimeRow = picker.selectedRow(inComponent: Predictor.crime.rawValue)
guard let crime = crimeDataSource.value(for: selectedCrimeRow) else {
return
}
let selectedRoomRow = picker.selectedRow(inComponent: Predictor.rooms.rawValue)
guard let rooms = roomsDataSource.value(for: selectedRoomRow) else {
return
}
guard let modelOutput = try? model.prediction(crime: crime, rooms: rooms) else {
fatalError("Something went wrong with generating the model output.")
}
// Estimated price is in $1k increments (Data is from 1970s...)
priceLabel.text = priceFormatter.string(for: modelOutput.price)
}
The first method in the code above is pickerView(_:didSelectRow:inComponent:), which is defined in the UIPickerViewDelegate protocol. We use this method to track new selections on our UIPickerView. These changes will trigger a call into our model to generate a new prediction from the newly selected values.
The second method is generatePrection(), which holds all of the logic to generate a prediction from our .mlmodel. Abstracting this logic into its own method makes it easier to update the label with a new prediction when the UIViewController’s viewDidLoad() method is called. As we saw above, this allows us to call generatePrediction() from within viewDidLoad().
generatePrediction() uses the picker’s state to determine the currently selected rows in each component. We use this information to ask our crimeDataSource and roomsDataSource for the values associated with these rows. For example, the crime rate associated with row index 3 is 0.03. Likewise, the number of rooms associated with row index 3 is 3.
We pass these values to our model to generate a prediction. The code that does our work there is try? model.prediction(crime: crime, rooms: rooms).
Note that we take a small shortcut here by using try? to convert the result into an optional to avoid the error should one arise. We could be a little better about error handling in this method, but that’s not the focus of this post. It’s also not so much of a problem in our case here because our model expects Doubles. The compiler will catch any mismatching types that we may pass in as arguments to the prediction(crime:rooms:) method. This method could theoretically throw, for example, if it were expecting an image, but we passed to it an image in an unexpected format.
For our current purposes, it’s sufficient for generating a prediction from our given inputs.
After we generate our prediction, we update the priceLabel’s text property with a well-formatted version of the price.
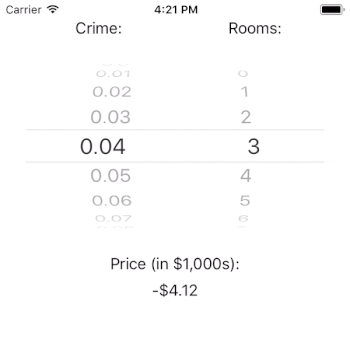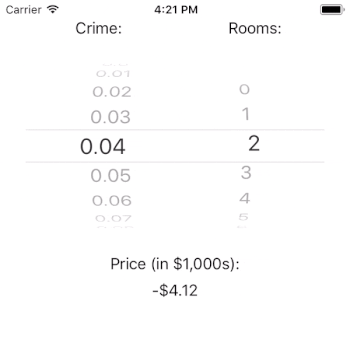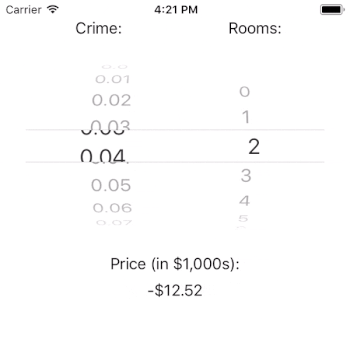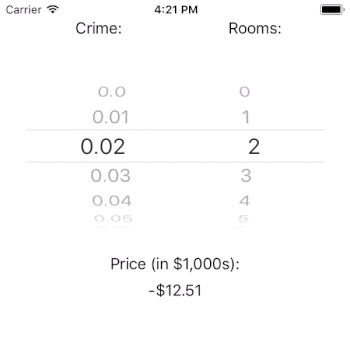
You may wonder why it is that the price can be predicted as negative. The answer lies in the important, but out of scope, work of model fit. The crux of the issue is that our model estimates that intercept to be very negative. This suggests that our model is underspecified in that it does not contain all of the independent variables that it needs to predict the outcome well. If we needed this model to perform well, we’d have to dig in here and figure out what is going on (or, we could just read Harrison and Rubinfeld’s paper).
Interestingly, it doesn’t look like crime rate has a large impact on the price of a home (given our model). That result could be a real finding, or it could be a flaw with our model. If this were a real app, it would certainly merit further investigation. Note, however, that the number of rooms has a tremendous impact on the estimated price of a house. This is just as we would expect.
Wrapping Up
This post walked through the process of using Core ML in an iOS app. With Core ML, we can take advantage of models that we have created in other tools directly within our apps. Core ML makes working with machine learning and statistical models more convenient and idiomatic.
Nonetheless, it is worth ending with a caveat. Statistics and machine learning are not simply APIs. They are entire fields of study that are equal parts art and science. Developing and selecting an informative model requires practice and study. Our app demonstrates this point pretty well: clearly there is something lacking in our model for predicting housing prices.
Core ML would likely be best leveraged by pairing a data scientist with an app team consisting of a mix of designers and developers. The data scientist would work on and tune the model to ensure that it delivers the best results. The app team would work on incorporating this model into the app to make sure that using it is a good experience that delivers value.
Yet some problems are more well-defined, and are matched with models that are already well-tested. These can be more easily “plugged into” your apps since you do not have to develop the model yourself. Examples of this include many classification problems: a) face detection, b) recognizing certain images, c) handwriting recognition, etc.
The tricky part with this approach will be making sure that the model you’ve selected is working well in your specialized case. This will involve some testing to make sure that the predictions the model is vending match what you expect. While it seems unlikely that Core ML will be able to make all modeling “plug and play”, it certainly does succeed in making it more accessible to app developers.
Learn more about why you should update your apps for iOS 11 before launch day, or download our ebook for a deeper look into how the changes affect your business.
The post Machine Learning in iOS Using Core ML appeared first on Big Nerd Ranch.
]]>The post Server-Side Swift with Vapor appeared first on Big Nerd Ranch.
]]>One of the most exciting parts of Swift being open-sourced is that it can be used as a more general purpose programming language.
Server side Swift is an especially appealing platform given the web’s ubiquity.
Recently, Apple began to support this initiative more formally by creating a working group dedicated to Swift on the server.
We at Big Nerd Ranch are very excited to see Swift on the server.
In this post, we’ll explore one popular project called Vapor.
We will create a small web app, see how to implement a few routes, connect to a database, perform some CRUD operations, and will deploy our app to Heroku.
The app that we’ll build will be a simple web API to save our friend information online.
It will allow us to save data to a database, which will be accessible via a few routes.
We’ll serve the data to clients via JSON.
Let’s get started.
Getting started
Xcode and Swift
The first thing you’ll need to get started with Swift on the server is Swift itself.
The easiest way to get Swift is to download Xcode from https://developer.apple.com.
You can download Xcode for free, and it comes with the latest version of Swift installed.
Vapor
The next thing that you’ll need is Vapor.
You can download Vapor and its toolbox from the documentation online.
Follow the information in the “Install Toolbox” section to get both Vapor and the toolbox so that you can use the vapor command line tool in the terminal.
Type vapor version to ensure that you have the toolbox installed correctly.
I see Vapor Toolbox v1.0.3 logged to the console.
Postgres
We’ll use Postgres as our database.
The easiest way to install Postgres is through Homebrew.
If you don’t have Homebrew installed already, you can download from the link provided.
After you install it, you can type brew install postgres in your terminal to download Postgres.
Type psql --version in the terminal to ensure that you have downloaded Postgres correctly, and you should see something like psql (PostgreSQL) 9.5.4.
Heroku
Heroku is a popular platform as a service (PaaS) that makes it very easy to get an app running on the web in a short amount of time.
It also works nicely with Swift.
You will need to create an account on Heroku to deploy via this platform.
Don’t worry; you can use a free account for the purposes of this post.
After you sign up for Heroku, make sure to download the Heroku command line interface.
Creating a Vapor Project
Let’s begin our project.
What we’re looking for is an app that will allow us to store our friends in a database.
We’ll expose an API that will allow us to create and read friends.
The Vapor toolbox can help you get started quickly.
Open up Terminal.app, and cd into a directory of your choosing.
Type vapor new Friends.
This will create a new Vapor project directory.
Your new Friends directory should look like this.
.
|--app.json
|--Config/
|--license
|--Localization/
|--Package.swift
|--Procfile
|--Public/
|--README.md
|--Resources/
|--Sources/
|--App/
|--Controllers/
|--main.swift
|--Models/
For the purposes of this tutorial, we’ll spend most of our time in Sources/App/main.swift and Package.swift.
One of the nice things about the Vapor toolbox is that we can easily create an Xcode project.
Type vapor xcode to create an Xcode project file that will allow us to use Xcode as our editor.
This command will fetch dependencies for the project, so it may take a little bit.
When the tool is finished fetching your project’s dependencies and generating your Xcode project, it will ask you if you’d like to open the project.
Type y in the console and hit enter to open the project.
With the project open, navigate to Sources/App/main.swift to view your app’s main point of entry.
You should see something like this:
import Vapor
let drop = Droplet()
drop.get { req in
return try drop.view.make("welcome", [
"message": drop.localization[req.lang, "welcome", "title"]
])
}
drop.resource("posts", PostController())
drop.run()
This file imports the Vapor framework, instantiates a Droplet, and adds a single route.
The instance of Droplet, drop, is responsible for running the server.
As you can see above, it’s what we use to register routes.
This route just gives a template greeting.
Setting up A Route
It’s time to set up our own routes.
Open main.swift and add a new route to GET some friends.
Make the route "friends" respond with a JSON object that is a dictionary that contains an array of the saved friends.
At this point, we don’t have a model type for our friend data or a database in place.
That means we will need to simply hardcode some JSON data and return that.
Your main.swift file should look like this now.
import Vapor
let drop = Droplet()
drop.get { req in
return try drop.view.make("welcome", [
"message": drop.localization[req.lang, "welcome", "title"]
])
}
drop.get("friends") { req in
return try JSON(node: ["friends": [["name": "Sarah", "age": 33],
["name": "Steve", "age": 31],
["name": "Drew", "age": 35]]
])
}
drop.resource("posts", PostController())
drop.run()
This new route accepts GET requests and returns some made up friend data as JSON.
It’s time to test what we have and see our Vapor app in action.
To run the application from Xcode, you will need to make sure to select the app scheme.
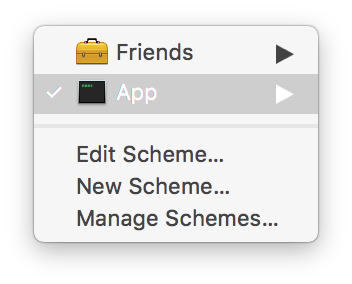
Now we can simply run the application from Xcode to get the app running on localhost on port 8080.
After building and running the application in Xcode, use your browser and navigate to “http://localhost:8080/friends”.
You should see the following response in your browser: {"friends":[{"age":33,"name":"Sarah"},{"age":31,"name":"Steve"},{"age":35,"name":"Drew"]}.
A Friend Model
It’d be better to have a Friend type; this would help us to avoid hard coding JSON instances.
Let’s add a Friend.swift file to Sources/App/Models.
struct Friend {
let name: String
let age: Int
let email: String
init(name: String, age: Int, email: String) {
self.name = name
self.age = age
self.email = email
}
}
(Note, that we have added an email property.)
Vapor provides a Model protocol that helps us to persist our model types.
Model also provides functionality that helps us to convert our models into JSON.
In order to have Friend conform to Model, we need to import the Vapor framework into our Friend.swift file.
Importing the Vapor framework will also import the Fluent framework.
Fluent is an object relational mapping (ORM) tool built for Swift that works with a variety of different databases.
We’ll be using it here to talk to our Postgres database.
If you’re seeing an error in Xcode that it doesn’t know about Vapor or Fluent, then go back to your Terminal and type vapor xcode to recreate the Xcode project.
After conforming to Model, your implementation of Friend should look like this:
import Foundation
import Vapor
struct Friend: Model {
var exists: Bool = false
var id: Node?
let name: String
let age: Int
let email: String
init(name: String, age: Int, email: String) {
self.name = name
self.age = age
self.email = email
}
// NodeInitializable
init(node: Node, in context: Context) throws {
id = try node.extract("id")
name = try node.extract("name")
age = try node.extract("age")
email = try node.extract("email")
}
// NodeRepresentable
func makeNode(context: Context) throws -> Node {
return try Node(node: ["id": id,
"name": name,
"age": age,
"email": email])
}
// Preparation
static func prepare(_ database: Database) throws {
try database.create("friends") { friends in
friends.id()
friends.string("name")
friends.int("age")
friends.string("email")
}
}
static func revert(_ database: Database) throws {
try database.delete("friends")
}
}
The first thing that we do is to conform to the Model protocol.
This means that we need to provide an id property that is of type Node?.
It will be nil until the model is saved to the database.
Friend also has a property called exists that defaults to false.
This property details whether or not the instance was retrieved from the database and should not be interacted with directly.
We also see that we need to conform to a series of other protocols.
The three protocols that are important are NodeInitializable, NodeRepresentable, and Preparation.
The first two protocols are needed because the Model protocol inherits from the Entity protocol, which itself inherits from the NodeInitializable and NodeRepresentable protocols.
The first helps us to know how to initialize our model from the database.
The second helps us to know how to save our model to the database.
The third helps us to create the database.
Let’s use this Model type instead of the dictionaries we provided to JSON in our "friends" route defined in main.swift.
Doing so put us in a good spot when we want to work with our Postgres database.
Your "friends" route should look like this now.
drop.get("friends") { req in
let friends = [Friend(name: "Sarah", age: 33, email:"sarah@email.com"),
Friend(name: "Steve", age: 31, email:"steve@email.com"),
Friend(name: "Drew", age: 35, email:"drew@email.com")]
let friendsNode = try friends.makeNode()
let nodeDictionary = ["friends": friendsNode]
return try JSON(node: nodeDictionary)
}
This time around we create an array called friends that contains the three instances of Friend we want to return for the GET request.
Next, we call makeNode() on this array to convert it to a Node.
Before we return anything, we make sure to properly format our response JSON to be a dictionary.
Last, we pass this nodeDictionary to JSON’s initializer and return the result.
Run your app again and visit “http://localhost:8080/friends”.
You should see something similar to what you had before, but this time you have a new email property.
We have now seen an example of setting up routes and creating model types in Vapor.
Before we add more routes, let’s connect to a database.
This will help our routes to be more useful as we won’t have to create and respond with arbitrary friend data.
Setting Up Postgres
Setting up Postgres involves a few steps.
- We need to add a provider for Postgres to our
Package.swiftfile. - We need to import the provider in
main.swiftand use it with ourDroplet. - We need to configure our app to use Postgres.
Getting a Postgres Provider
A good provider for Postgres in Vapor is postgres-provider.
Add this dependency to Package.swift.
import PackageDescription
let package = Package(
name: "Friends",
dependencies: [
.Package(url: "https://github.com/vapor/vapor.git", majorVersion: 1, minor: 1),
.Package(url: "https://github.com/vapor/postgresql-provider", majorVersion: 1, minor: 0)
],
exclude: [
"Config",
"Database",
"Localization",
"Public",
"Resources",
"Tests",
]
)
Regenerate your Xcode project with vapor xcode to fetch the new dependency.
Make sure to type y in your console when it’s done so that you can open the new Xcode project.
Importing the Provider
Now, it’s time to use Postgres in your code.
Open main.swift and prepare the database for use.
import Vapor
import VaporPostgreSQL
let drop = Droplet()
drop.preparations.append(Friend.self)
do {
try drop.addProvider(VaporPostgreSQL.Provider.self)
} catch {
assertionFailure("Error adding provider: (error)")
}
drop.get { req in
return try drop.view.make("welcome", [
"message": drop.localization[req.lang, "welcome", "title"]
])
}
drop.get("friends") { req in
let friends = [Friend(name: "Sarah", age: 33, email:"sarah@email.com"),
Friend(name: "Steve", age: 31, email:"steve@email.com"),
Friend(name: "Drew", age: 35, email:"drew@email.com")]
let friendsNode = try friends.makeNode()
let nodeDictionary = ["friends": friendsNode]
return try JSON(node: nodeDictionary)
}
drop.resource("posts", PostController())
drop.run()
First, we import VaporPostgreSQL so that we can use the Postgres provider in our code.
We then add Friend.self to our Droplet’s preparations so that we can use our model with the database.
Last, drop.addProvider(VaporPostgreSQL.Provider.self) adds our provider to the droplet so that the database is available.
The rest of main.swift remains the same.
Configuring the Project to Use Postgres
Our next step is to create a configuration file for Postgres.
The README.md for our provider has instructions that tell us that we need to create the following file: Config/secrets/postgresql.json.
The Config folder should already exist, but you may have to create the secrets folder.
The README.md also suggests what we should put in this file.
{
"host": "127.0.0.1",
"user": "DubbaDubs",
"password": "",
"database": "friends",
"port": 5432
}
Use your own username for "user".
Notice that we name our database "friends".
We still need to create it.
We’ll do that below.
Using Postgres
With Postgres set up, and our Friend struct conforming to Model, we are in a good spot to write some routes that get their data from the database.
Let’s add a route to main.swift that will POST a new Friend and save it to our database.
import Vapor
import VaporPostgreSQL
let drop = Droplet()
drop.preparations.append(Friend.self)
do {
try drop.addProvider(VaporPostgreSQL.Provider.self)
} catch {
print("Error adding provider: (error)")
}
drop.get { req in
return try drop.view.make("welcome", [
"message": drop.localization[req.lang, "welcome", "title"] ])
}
drop.get("friends") { req in
let friends = [Friend(name: "Sarah", age: 33, email:"sarah@email.com"),
Friend(name: "Steve", age: 31, email:"steve@email.com"),
Friend(name: "Drew", age: 35, email:"drew@email.com")]
let friendsNode = try friends.makeNode()
let nodeDictionary = ["friends": friendsNode]
return try JSON(node: nodeDictionary)
}
drop.post("friend") { req in
var friend = try Friend(node: req.json)
try friend.save()
return try friend.makeJSON()
}
drop.resource("posts", PostController())
drop.run()
We now have a route to POST a Friend.
This route expects a body like this:
{
"name": "Some Name",
"age": 30,
"email": "email@email.com"
}
We try to create an instance of our Friend model with the req.json that was passed up in the POST request.
The next step is to call friend.save() to save the instance to the database.
This helps to explain why friend needed to be a var: save() will modify the instance’s id property with the id Postgres hands back if the save succeeds.
We still need to create our database.
Type postgres -D /usr/local/var/postgres/ into Terminal to start the Postgres server running locally.
Once the server has started up, we can create the database.
In a new Terminal window, type createdb friends and hit enter.
Next, type psql and hit enter to start the Postgres command line interface.
Last, type l (backslash l) to see a list of databases.
You should see your friends database.
You can test this new route by building and running your app within Xcode as you did above and using curl or a tool like Postman.
You can use psql to verify that you are posting data to the database.
From inside the command line interface, type c friends to connect to your friends database.
Next, type SELECT * FROM friends; and hit enter.
You should see the information for the friend that you just POSTed to the "friend" route.
Removing Hardcoded Data
GET requests to our "friends" currently return hardcoded data.
But we can POST friends to our database now!
Go ahead and POST a few more friends to your database to fill it out a little more.
Back in main.swift, let’s update our "friends" route to return the data in our database.
That method should now look like this:
drop.get("friends") { req in
let friends = try Friend.all().makeNode()
let friendsDictionary = ["friends": friends]
return try JSON(node: friendsDictionary)
}
Visit http://localhost:8080/friends in your browser or send a GET request via Postman and you should see your friends returned to you.
GETting by id
Add a new route to main.swift that will use a user’s id to find an entry in the database.
drop.get("friends", Int.self) { req, userID in
guard let friend = try Friend.find(userID) else {
throw Abort.notFound
}
return try friend.makeJSON()
}
The above will match a route that will end in something like, .../friends/1, where the integer at the end is the friend’s id.
Notice that we use Int.self as the second argument in the path.
This means that we can have type safe parameters in our routes!
In Vapor, there is no need to cast this parameter from a String to an Int.
We can express exactly what we need.
The userID parameter in the closure will match the integer passed at the end of the route.
Also, through the power of Fluent, we can simply find(_:) the instance of our model by its id.
Since this lookup can fail, we must try.
If we fail to find a Friend, we’ll throw the error Abort.notFound.
Otherwise, we makeJSON() from the friend we found and return.
Go ahead and try it out!
Deploying to Heroku
All that is left to do is to deploy to Heroku.
Vapor makes this process very easy.
Heroku works with Git, so you should make sure that you have that installed as well.
Create a Git repository and commit your files.
git init
git add .
git commit -m "Initial commit"
Now, all you need to do is create a Heroku instance and push to it.
vapor heroku init
The Heroku CLI will ask four questions:
Would you like to provide a custom Heroku app name?
Answer ‘n’ and hit enter if you don’t have a custom name.
Would you like to provide a custom Heroku buildpack?
Answer ‘n’ and hit enter if you would like to use the default buildpack that Heroku provides.
Are you using a custom Executable name?
Answer ‘n’ and hit enter here if you aren’t using a custom executable name.
Would you like to push to Heroku now?
Answer ‘n’ and hit enter.
We need to answer ‘no’ because we need to configure our database to work online.
We’ll do that below.
Before you plug the URL you see in your Terminal output into your browser of choice, we need to provision a Postgres add-on on Heroku.
Type the following in your Terminal to add Postgres to your app.
heroku addons:create heroku-postgresql:hobby-dev
Adding the database can take up to five minutes to provision.
Once it is ready, you can type heroku config in Terminal to see your database’s URL to confirm that the add-on was provisioned.
Now, we need to update our app’s Procfile, which was created via vapor heroku init, to use the DATABASE_URL environment variable that was created by Heroku.
Open the Procfile in your text editor and update it so that looks like the below.
web: App --env=production --workdir="./"
web: App --env=production --workdir=./ --config:servers.default.port=$PORT --config:postgresql.url=$DATABASE_URL
Notice that we added a new configuration so that Heroku knows to use our database’s URL on the web and not the instance we have been running locally: --config:postgresql.url=$DATABASE_URL.
Save the Procfile and type git push heroku master in Terminal to deploy your app.
Deploying will take a few minutes.
Heroku needs to build your application, install Swift on your Heroku instance, and so on. After some time, your app will be live on the web.
Note that we didn’t push up the data from the local database to the remote database. You will have to exercise your app’s API to add some data to your database on Heroku.
Making Changes
Making changes is easy!
Simply write your code, commit the changes, and push them up to Heroku.
git commit -am "Adds new code"
git push heroku master
Wrapping Up
This post covered a lot of ground: We downloaded a number of tools.
Introduced Vapor.
Wrote a small web app.
Developed an API to read and write some data to Postgres.
Finally, we deployed the app to Heroku.
This post is intended to you get started with server-side Swift. To that end, we introduced Vapor and explored some of its features. But this introduction just scratches the surface; there is a lot more to Vapor. What’s exciting is that server-side Swift is moving fast! Stay tuned here for more posts on the subject.
Challenges
If you’re looking for more to do on your own, try your hand at these extra challenges.
- Create a route to
DELETEa friend from the database. - Create a route to
PATCHa friend on the database.
The post Server-Side Swift with Vapor appeared first on Big Nerd Ranch.
]]>The post Using Swift Enumerations Makes Segues Safer appeared first on Big Nerd Ranch.
]]>Swift style encourages developers to use the compiler to their advantage, and one of the ways to accomplish this is to leverage the type system. In many cases, doing so can feel fairly obvious, but working with UIKit can be challenging since it often hands you String instances to identify view controllers, storyboards and so on. We have received some guidance on this issue in the form of a WWDC session in 2015, but it’s a good idea to revisit the problem to continue our practice of thinking Swiftly.
Let’s take a look at storyboard segues as our example, which can be especially tricky. One of the difficulties arises from the fact that UIKit requires that we use a String to identify the segue that we want to use. That means, in a sense, that UIStoryboardSegues are “stringly” typed. This makes it difficult to work with segues in a type-safe manner, and can lead to a lot of repetitive code. How can we address this problem?
A Naive Approach to Storyboard Segues
You may have seen something like this out in the wild. You may have even written this code before (gasp!).
// Sitting somewhere in the source for a UIViewController
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
guard let identifier = segue.identifier else {
assertionFailure("Segue had no identifier")
return
}
if identifier == "showPerson" {
let person = Person(name: "Matt")
let personVC = segue.destination as! PersonViewController
personVC.person = person
} else if identifier == "showProduct" {
let product = Product(title: "Book")
let productVC = segue.destination as! ProductViewController
productVC.product = product
} else {
assertionFailure("Did not recognize storyboard identifier")
}
}
Here, we have a prepare(for:sender:) method overridden in a UIViewController.
It grabs the identifier from the inbound segue, and then matches against a couple of hardcoded strings.
These strings, like "showPerson" and "showProduct", will match a segue seeking to show a PersonViewController or a ProductViewController.
This approach is overly mechanical, which can lead to buggy code.
It is easy to mistype the segue identifiers.
It is also easy to forget to add a new segue identifier to this list.
Forgetting to capture an identifier in one of the else clauses above would make for a likely crash in the next view controller.
Notice that we use assertionFailure() above and not preconditionFailure().
assertionFailure() will be caught in debug mode, whereas preconditionFailure() will crash in both debug and release build configurations.
This is perfect for testing your application while you are developing it.
Ideally, we aim to capture all of these sorts of bugs during our development cycle.
In the unfortunate circumstance that we do not, it is worth it to let our segue proceed as usual.
It’s possible that things will go okay and that the subsequent view controller will have the data it needs—of course, this depends upon the data and circumstances at hand, but it is good to let the app proceed if it makes sense.
Preemptively crashing with preconditionFailure() is not always the best option.
A Type-safe Approach
There has to be a better way.
What we are looking for is something that will help us to catch these errors before we ever get to the runtime.
How can we catch this sort of error before we get there?
Enumerations Make Segues Safer
Let’s take a moment to examine the if/else statement we have above.
Notice that we have several clauses; this is no simple if/else.
A general rule of thumb to recall is that if an if/else statement has multiple clauses, then it may be suitable to replace it with a switch statement.
Let’s see what that looks like.
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
guard let identifier = segue.identifier! else {
assertionFailure("Segue had no identifier")
return
}
switch identifier {
case "showPerson":
let person = Person(name: "Matt")
let personVC = segue.destination as! PersonViewController
personVC.person = person
case "showProduct":
let product = Product(title: "Book")
let productVC = segue.destination as! ProductViewController
productVC.product = product
default:
assertionFailure("Did not recognize storyboard identifier")
}
}
Refactoring to a switch statement helps us to see the path forward.
Switching over a String like identifier feels a little buggy.
Instead of switching over a String, we’d rather switch over something whose set of possible values is more determined.
Enumerations are perfect in this scenario.
Let’s think about what is needed.
Obviously, we need to replace to replace the identifier String with an enumeration case.
We can do this with an enumeration whose raw values are Strings.
This will allow us to define a type whose cases comprise the segues we anticipate to be passed to prepare(for:sender:).
It will also yield an enumeration whose cases are backed by String instances.
String raw values will be nice when we need to match against the incoming segue’s identifier.
Here’s an enumeration that defines cases for the segues we have seen so far.
extension ViewController {
enum ViewControllerSegue: String {
case showPerson
case showProduct
}
}
I like to define this enumeration as a nested type within its associated UIViewController.
It helps to make the relationship clear: The view controller is what helps to prepare for a segue before it is performed.
In the example at hand, ViewControllerSegue is simply there to help out by providing comprehensive information to the compiler.
How does this work?
Well, we need to modify our override of prepare(for:sender:) above.
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
guard let identifier = segue.identifier,
let identifierCase = ViewController.ViewControllerSegue(rawValue: identifier) else {
assertionFailure("Could not map segue identifier -- (segue.identifier) -- to segue case")
return
}
switch identifierCase {
case .showPerson:
let person = Person(name: "Matt")
let personVC = segue.destination as! PersonViewController
personVC.person = person
case .showProduct:
let product = Product(title: "Book")
let productVC = segue.destination as! ProductViewController
productVC.product = product
}
}
This implementation of prepare(for:sender:) leverages our new enumeration.
Its first task is to get the identifier associated with the segue and transform it into an instance of ViewControllerSegue.
If this fails, then you assertionFailure() with the relevant debug information.
Otherwise, you have the information you need to safely switch over the segue.identifier.
Finally, the switch we use exhaustively checks all of the possible cases.
This helps in a couple of ways.
First, the switch allows us to avoid repeating the calls to assertionFailure().
We are able to avoid this redundancy because the switch can determine whether or not we are covering all of the enumeration’s cases.
Second, this switch can also warn us if we forget to cover a new segue.
The best path here is that we remember to add a new case to our ViewControllerSegue enumeration.
Doing so will trigger the compiler to issue an error in the above switch if it does not cover the new case.
If we forget to add the new segue identifier case to our enumeration, then we will hit the assertionFailure() within our guard statement during our testing.
Either way, the above code is less repetitive and gives more information to the compiler to help us avoid bugs at runtime.
Eliminating Redundancy Through Protocol Extensions
While we are on the topic of making our code less repetitive, let’s rethink our approach.
Currently, every view controller that wants to take advantage of the segue enumeration will need to remember to do two things.
First, it will need to provide an enumeration with cases for all of the segues that it needs to handle.
Second, it will need to write the guard statement above in prepare(for:sender) to map the segue.identifier to a segue case in the enumeration.
That will get a little tedious to remember to type every time we make a new UIViewController subclass.
Protocol extensions can help to alleviate this issue.
protocol SegueHandler {
associatedtype ViewControllerSegue: RawRepresentable
func segueIdentifierCase(for segue: UIStoryboardSegue) -> ViewControllerSegue?
}
The protocol above uses an associatedtype named ViewControllerSegue. Conforming types will have to provide a nested type of the same name enumerating all of the segues the view controller expects to handle. These nested types will have to be RawRepresentable, which will work well with our String backed segue cases. Last, the protocol requires a method that will take a UIStoryboardSegue and map to an of the nested enumeration. This method returns an optional to handle the scenario of not being able to map the segue.identifier to a specifc case on the nested enumeration.
We can use a protocol extension to provide a default implementation of the required method above.
extension SegueHandler where Self: UIViewController, ViewControllerSegue.RawValue == String {
func segueIdentifierCase(for segue: UIStoryboardSegue) -> ViewControllerSegue {
guard let identifier = segue.identifier,
let identifierCase = ViewControllerSegue(rawValue: identifier) else {
return nil
}
return identifierCase
}
}
Now all you have to do on your UIViewController subclasses is to declare conformance to the SegueHandler protocol.
Doing so will nudge the compiler to issue you an error if your view controller does not provide the nested type ViewControllerSegue.
(Remember that you listed this requirement in the protocol via an associatedtype.
Now, heading back to ViewController, our prepare(for:segue) method looks like so:
// extension ViewController: SegueHandler {} somewhere in the file...
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
guard let identifierCase = segueIdentifierCase(for: segue) else {
assertionFailure("Could not map segue identifier -- (segue.identifier) -- to segue case")
return
}
switch identifierCase {
case .showPerson:
let person = Person(name: "Matt")
let personVC = segue.destination as! PersonViewController
personVC.person = person
case .showProduct:
let product = Product(title: "Book")
let productVC = segue.destination as! ProductViewController
productVC.product = product
}
}
This is a bit nicer, but it can get better.
We’ve written a protocol and protocol extension to handle the mapping from segue.identifier to segue enumeration case.
This is great because conforming UIViewController subclasses will get some help from the compiler to ensure that we provide the correct enumeration for our view controller’s segues.
But we still have a guard statement above, and that’s because we currently have segueIdentifierCase(for:) returning an optional.
It would be nicer to not have to worry about optionals.
What about Segues with No Identifiers?
Before we update segueCaseIdentifier(for:) to not return an optional, let’s talk about segues without identifiers.
Our current approach means that we will trap in the guard statement above if our segue doesn’t have an identifier.
This really isn’t a problem because all of our segues should have an identifier.
But, you say, I dont need an identifier because I’m not passing any data to the next view controller.
I just need to show it.
Okay, okay.
Unnamed segues have an empty String identifier: "".
Let’s add a new unnamed case to ViewControllerSegue.
extension ViewController {
enum ViewControllerSegue: String {
case showPerson
case showProduct
case unnamed = ""
}
}
The compiler is now bugging us that we need to make our switch statement exhaustive in prepare(for:sender:) above, so let’s add the new case.
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
guard let identifierCase = segueIdentifierCase(for: segue) else {
assertionFailure("Could not map segue identifier -- (segue.identifier) -- to segue case")
return
}
switch identifierCase {
case .showPerson:
let person = Person(name: "Matt")
let personVC = segue.destination as! PersonViewController
personVC.person = person
case .showProduct:
let product = Product(title: "Book")
let productVC = segue.destination as! ProductViewController
productVC.product = product
case .unnamed:
assertionFailure("Segue identifier empty; all segues should have an identifier.")
}
}
Notice that we use assertionFailure() again to accomodate for the possibility that our app won’t crash at runtime, but also to give us the nudge during our development that we really ought to provide an identifier to the segue.
Now that we have a new case, we are in a good position to revisit our default implementation of segueCaseIdentifier(for:).
extension SegueHandler where Self: UIViewController, ViewControllerSegue.RawValue == String {
func segueIdentifierCase(for segue: UIStoryboardSegue) -> ViewControllerSegue {
guard let identifier = segue.identifier,
let identifierCase = ViewControllerSegue(rawValue: identifier) else {
fatalError("Could not map segue identifier -- (segue.identifier) -- to segue case")
}
return identifierCase
}
}
This new default implementation uses fatalError().
Why did we make this change?
The answer has to do with the new ViewControllerSegue.unnamed case.
This case acts as a kind of friendly default case for our switch statement.
All unnamed segues will match against this case.
I call this a “friendly” default case because it won’t ruin our switch’s attempts at being exhaustive.
If we add a new case, then the compiler will see that our switch doesn’t match against it and issue an error.
Therefore, segueIdentifierCase(for:) should never fail to generate a ViewControllerSegue.
If it receives an empty string (in the case of a segue without an identifier), then it will create an instance of ViewControllerSegue set to .unnamed.
It may receive a segue with an identifier that doesn’t match a case in our enumeration, which would be bad.
After all, we have an .unnamed case, which means that we purposefully chose to give the segue an identifier.
That suggests we need to pass that view controller some data.
This sounds like an unrecoverable error, and so crashing is the right way to go.
We can finally head back to prepare(for:sender:) to remove the optional unwrapping and streamline our code.
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
switch segueIdentifierCase(for: segue) {
case .showPerson:
let person = Person(name: "Matt")
let personVC = segue.destination as! PersonViewController
personVC.person = person
case .showProduct:
let product = Product(title: "Book")
let productVC = segue.destination as! ProductViewController
productVC.product = product
case .unnamed:
assertionFailure("Segue identifier empty; all segues should have an identifier.")
}
}
Since segueIdentifierCase(for:) doesn’t return an optional, we can simply switch over its result.
Wrapping Up
UIKit’s API often expects to receive and hands back String instances to interface with storyboards, view controllers and segues.
This can lead to buggy code. For example, it’s easy to mistype the String used to identify the item you need.
One useful way we can improve our interaction with UIKit is to leverage Swift’s type system to limit our options.
Enumerations are especially suited for this work as they define a precise listing of options for a type.
Swift’s enumerations work perfectly here because we can back each case’s raw value with a String that corresponds to a specifc resource.
We can also use protocols and protocol extensions to help. Using these help to remove redundancy in our code. They also leverage the compiler’s knowledge of the protocol’s requirements to remind us to write safer code.
The post Using Swift Enumerations Makes Segues Safer appeared first on Big Nerd Ranch.
]]>The post WWDC 2016: Increased Safety in Swift 3.0 appeared first on Big Nerd Ranch.
]]>Since its release, Swift has emphasized safety, and optionals are an important part of Swift’s approach. They provide a mechanism for representing nil, and require a definite syntax for working with an instance that may be nil.
Optionals come in two forms:
OptionalImplicitlyUnwrappedOptional
The first is the safe kind: it requires the developer to unwrap the optional in order to access the underlying value. The second is the unsafe kind: developers can directly access the underlying value without unwrapping the optional. Thus, working with ImplicitlyUnwrappedOptionals can result in a bad access if the underlying value is nil.
This problem can be summarized like so:
let x: Int! = nil
print(x) // Crash! `x` is nil!
Swift 3.0 changes the semantics of ImplicitlyUnwrappedOptional, and is even safer than its previous incarnations. What has changed in Swift 3.0 for this type that improves the language’s safety? The answer has to do with improvements in how the compiler infers type information for ImplicitlyUnwrappedOptional.
The Old Way: Swift 2.x
Let’s take a look at an example to understand the change.
struct Person {
let firstName: String
let lastName: String
init!(firstName: String, lastName: String) {
guard !firstName.isEmpty && !lastName.isEmpty else {
return nil
}
self.firstName = firstName
self.lastName = lastName
}
}
We have a struct Person with a failable initializer. If we do not supply a person with a first and last name, then the initializer fails.
The initializer is declared with a ! and not a ?: init!(firstName: String, lastName: String).
We use init! here simply to make a point of how ImplicitlyUnwrappedOptionals work in Swift 2.x vs. Swift 3.0. init! should be used sparingly regardless of the version of Swift you are using. Generally speaking, you’ll want to use init! when you want accesses to the resulting instance to lead to a crash if the instance is nil.
In Swift 2.x, this initializer would yield an ImplicitlyUnwrappedOptional<Person>. If the initializer failed, then accessing the underlying Person instance would generate a crash.
For example, in Swift 2.x the following would crash:
// Swift 2.x
let nilPerson = Person(firstName: "", lastName: "Mathias")
nilPerson.firstName // Crash!
Notice that we don’t have to use optional binding or chaining to try to access a value on nilPerson because it was implicitly unwrapped by the initializer.
The New Way: Swift 3.0
Things are different with Swift 3.0. The ! in init! indicates that the initialization process can fail, and if it doesn’t, that the resulting instance may be forced (i.e., implicitly unwrapped). Unlike in Swift 2.x, instances resulting from init! are Optionals and not ImplicitlyUnwrappedOptionals. That means you will have to employ optional binding or chaining to access the underlying value.
// Swift 3.0
let nilPerson = Person(firstName: "", lastName: "Mathias")
nilPerson?.firstName
In this reprise of the example above, nilPerson is now an Optional<Person>. Thus, nilPerson needs to be unwrapped if we want to access its value. The usual machinery for optional unwrapping is appropriate here.
Safety and Type Inference
This change may feel unintuitive. Why is the initializer, which was declared with init!, creating a regular Optional? Doesn’t that ! at the end of init mean that it should create an ImplicitlyUnwrappedOptional?
The answer depends upon the relationship between being safe and being declarative. Remember that the code above (namely: let nilPerson = Person(firstName: "", lastName: "Mathias")) relied upon the compiler to infer the type of nilPerson.
In Swift 2.x, the compiler would infer nilPerson to be ImplicitlyUnwrappedOptional<Person>.
We got used to this, and it made some sense. After all, the initializer at play above was declared with init!.
Nonetheless, this isn’t quite safe. We never explicitly declared that nilPerson should be an ImplicitlyUnwrappedOptional. And it’s not great that the compiler inferred unsafe type information.
Swift 3.0 solves this problem by treating ImplicitlyUnwrappedOptionals as Optional unless we explicitly declare that we want an ImplicitlyUnwrappedOptional.
Curtailing the Propagation of ImplicitlyUnwrappedOptional
The beauty of this change is that it curtails the propagation of implicitly unwrapped optionals. Given our definition for Person above, consider what we would expect in Swift 2.x code:
// Swift 2.x
let matt = Person(firstName: "Matt", lastName: "Mathias")
matt.firstName // `matt` is `ImplicitlyUnwrappedOptional<Person>`; we can access `firstName` directly
let anotherMatt = matt // `anotherMatt` is also `ImplicitlyUnwrappedOptional<Person>`
anotherMatt is created with the exact same type information as matt. You may have expected that to be the case, but it isn’t necessarily desirable. The ImplicitlyUnwrappedOptional has propagated to another instance in our code base. There is yet another line of potentially unsafe code that we have to be careful with.
For example, what if there were something asynchronous about the code above (a stretch, I know…)?
// Swift 2.x
let matt = Person(firstName: "Matt", lastName: "Mathias")
matt.firstName // `matt` is `ImplicitlyUnwrappedOptional<Person>`, and so we can access `firstName` directly
... // Stuff happens; time passes; code executes; `matt` is set to nil
let anotherMatt = matt // `anotherMatt` has the same type: `ImplicitlyUnwrappedOptional<Person>`
In this contrived example, anotherMatt is nil, which means any direct access to its underlying value will lead to a crash. But this sort of access is exactly what ImplicitlyUnwrappedOptional encourages. Wouldn’t it be better if anotherMatt’s type was Optional<Person>?
That is exactly the case in Swift 3.0!
// Swift 3.0
let matt = Person(firstName: "Matt", lastName: "Mathias")
matt?.firstName // `matt` is `Optional<Person>`
let anotherMatt = matt // `anotherMatt` is also `Optional<Person>`
Since we do not explicitly declare that we want an ImplicitlyUnwrappedOptional, the compiler infers the safer Optional type.
Type Inference Should be Safe
The main benefit in the change is that type inference no longer automatically makes our code less safe. If we choose to not be safe, then we should have to be explicit about it. The compiler should not make that choice for us.
If we want to use an ImplicitlyUnwrappedOptional for whatever reason, then we still can. We just have to explicitly declare that we want to be unsafe.
// Swift 3.0
let runningWithScissors: Person! = Person(firstName: "Edward", lastName: "") // Must explicitly declare Person!
let safeAgain = runningWithScissors // What's the type here?
runningWithScissors is nil because the initializer was given an empty String for lastName.
Notice that we declared runningWithScissors to be an ImplicitlyUnwrappedOptional<Person>. If we want to run through the house with scissors in both hands, then Swift will let us. But Swift wants us to be explicit about it; we must specifically declare that we know we want an ImplicitlyUnwrappedOptional.
Thankfully, however, the compiler does not infer safeAgain to be an ImplicitlyUnwrappedOptional. Instead, the compiler dutifully hands us a very safe Optional<Person>. Swift 3.0 seeks to curtail the unwitting propagation of unsafe code by default.
The Future
ImplicitlyUnwrappedOptional now behaves more similarly to the intent behind its purpose: it exists to facilitate how we interact with APIs for whom nullability is meaningful or the return type cannot be known. Both of these are often true in Objective-C, which Swift needs in order to do work on macOS or iOS.
But pure Swift seeks to eschew these problems. Thanks to the changes to ImplicitlyUnwrappedOptional, we are now in an even better position to transcend them. Imagine: a future without ImplicitlyUnwrappedOptionals.
Further Information
If you’re curious to read more, then see this proposal for further information. You’ll see how the proposal’s authors thought through this issue, and get a little more detail on the change. There is also a link to a thread where the community discussed the proposal.
The post WWDC 2016: Increased Safety in Swift 3.0 appeared first on Big Nerd Ranch.
]]>The post Protocol-Oriented Problems and the Immutable ‘self’ Error appeared first on Big Nerd Ranch.
]]>Protocol-oriented programming is a design paradigm that has a special place in Swift, figuring prominently in Swift’s standard library. Moreover, protocol-oriented programming leverages Swift’s features in a powerful way.
Protocols define interfaces of functionality for conforming types to adopt, providing a way to share code across disparate types. By conforming to protocols, value types are able to gain features outside of their core definition despite their lack of inheritance. Furthermore, protocol extensions allow developers to define default functionality in these interfaces. And so, conforming types can gain an implementation simply by declaring their conformance. These features allow you to produce more readable code that minimizes interdependencies between your types, and also allows you to avoid repeating yourself.
That said, there are practical concerns. Protocols can sometimes seem to force a decision between whether you want both value types and reference types to be able to conform. Obviously, this decision has the potential to limit the application and usability of a given protocol. This post provides an example where the developer may want to make this limiting choice, elucidates the tensions in making the decision, and discusses some strategies in moving forward.
An Example
Here is a simple example that provides a Direction enum, a VehicleType protocol and a class Car that conforms to the protocol. There is also a protocol extension that provides a default implementation for a method required by the VehicleType protocol.
enum Direction {
case None, Forward, Backward, Up, Down, Left, Right
}
protocol VehicleType {
var speed: Int { get set }
var direction: Direction { get }
mutating func changeDirectionTo(direction: Direction)
mutating func stop()
}
extension VehicleType {
mutating func stop() {
speed = 0
}
}
class Car: VehicleType {
var speed = 0
private(set) var direction: Direction = .None
func changeDirectionTo(direction: Direction) {
self.direction = direction
if direction == .None {
stop()
}
}
}
If you have been typing along with this example, you should see the following error within the changeDirectionTo(_:) method’s implementation:

What does “Cannot use mutating member on immutable value: ‘self’ is immutable” mean?
Understanding the Error
There are three insights that help to clarify the error.
- Recall that the protocol
VehicleTypedeclares thatstop()is amutatingmethod. We declared it like this becausestop()changes the value of a property,speed, and we are required to mark it asmutatingin case value types conform. VehicleType’s protocol extension provides a default implementation forstop().Caris a reference type.
mutating
mutating methods signal to the compiler that calling a method on a value type instance will change it. The mutating keyword implicitly makes the instance itself—self—an inout parameter, and passes it as the first argument into the method’s parameter list. In other words, the compiler expects stop() to mututate self.
VehicleType’s Protocol Extension
The protocol extension provides a default implementation for stop() that simply sets the vehicle’s speed property to 0. Since it modifies a property, it needs to be declared as mutating. This declaration of mutating is significant: all conforming types will have an implementation of stop() that is mutating.
Car is a Reference Type
Notice that we call stop() within Car’s implementation of changeDirectionTo(_:). If the new direction is .None, then we infer that the Car instance needs to stop. But here is where the problem occurs.
Putting it all Together
stop() is a mutating method, with a default implementation, that the compiler expects will change self. But Car is a reference type. That means the self—the reference to the Car instance that is used to call stop()—that is available within changeDirectionTo(_:) is immutable!
Thus, the compiler gives us an error because stop() wants to mutate self, but the self available within changeDirectionTo(_:) is not mutable.
Three Solutions
There are three principal ways to solve this problem.
- Implement a non-
mutatingversion ofstop()onCar. - Mark the
VehicleTypeprotocol as class only:protocol VehicleType: class { ... }. - Make
Cara struct.
A Non-mutating Version of stop()
One solution is to implement a non-mutating version of stop() on Car. At first glance, this may appear to be the most flexible solution. It preserves the ability of value types to conform to VehicleType, and maintains its relevance to reference types as well.
It is important to understand that a mutating method and a non-mutating method are not the same. mutating methods have a different parameter list than a non-mutating method. A mutating method’s first parameter is expected to be inout, with the remainder of the parameter list being same. A non-mutating method does not include this first inout parameter. Thus, you are not quite repeating yourself in strict sense—they are indeed different methods.

The first signature for stop() in the image refers to the implementation that we just added to Car. The second refers to the default implementation that was added in the protocol extension. Thus, our implementation of stop() on Car adds a whole new method that provides clarity and context.
If we choose this solution, our Car class now looks like so:
class Car: VehicleType {
var speed: Int = 0
private(set) var direction: Direction = .None
func stop() {
speed = 0
}
func changeDirectionTo(direction: Direction) {
self.direction = direction
if direction == .None {
stop()
}
}
}
Choosing Class
The next two solutions make for a different decision: should the VehicleType protocol apply to classes, value types or both (as above)?
Choosing a class-only protocol will solve the problem insofar that we will have to remove mutating keywords from the protocol’s declaration. Conforming types will have to be classes, and will thereby not have to worry about the added confusion resulting from having a default implementation of a mutating method. In this way, the protocol becomes a bit more clear in its specificity.
Choosing Value Types
Choosing a value-type-only protocol is not technically possible. There is no syntax available for limiting a protocol in this way (e.g., protocol VehicleType: value { ... } syntax). If you want to pursue this route, you would leave the protocol as it currently is, and change Car to be a struct. Perhaps it would be useful to add some documentation to VehicleType so that users can see that it is intended for value types only:
/// `VehicleType` is a protocol that is intended only for value types.
protocol VehicleType {
// protocol requirements here
}
This option is appealing if you have no good reason to make Car a class. In Swift, we often start writing our models as a value type before reaching for the complexity of a reference type. More still, if you follow the advice in the video linked to above, you may even want to start your modeling by defining a protocol. Either way, reaching for a class should not be your first choice unless you absolutely know that you need a class.
What Should You Do?
The more flexible solution presented above suggests that perhaps there is good reason for Car to be a class. If that is the case, then stop() will have special meaning there (i.e., it will need to not be mutating). More specifically,stop() will be a different method on a class that it will be on a value type.
And perhaps there are also good reasons for value types to conform to VehicleType But if this is true, then there are some issues to think about. There are three disadvantages to taking the more ‘flexible’ path.
-
Allowing both value types and reference types to conform to
VehicleTypemakes the code a bit more complex. Readers of our code will have to take some time and think about the differences between implementations ofstop()on classes vs implementations ofstop()on value types. -
Choosing the flexible option means that you will likely have to type more code. You will have to provide non-
mutatingimplementations of eachmutatingmethod required by the protocol that has a default implementation. This code will feel like you are repeating yourself, which is not great. -
Finally, and perhaps more importantly, you should be asking yourself if your architecture is getting confusing. Is this protocol providing an interface that you want your model types to conform to? In the example here,
VehicleTypesuggests that this protocol provides an interface to model types. If you find yourself in a similar situation, it probably doesn’t make sense for your model types to variously be either classes or value types if your models need the functionality listed in theVehicleTypeprotocol.
For example, your models will probably need to take advantage of Core Data, KVO and/or archiving. If any of these are the case, then you’ll want to restrict conformance to your protocol to classes. If any of these are not actually the case, then perhaps you will want to restrict conformance (at least, informally by way of inline documentation) to value types.
A very informal glance at the Swift standard library suggests that every protocol that includes the mutating keyword is intended to be conformed to by a value type (e.g., CollectionType). One simple rule of thumb here may be that if you use the keyword mutating in a protocol, then you are intending for only value types to conform to it.
The post Protocol-Oriented Problems and the Immutable ‘self’ Error appeared first on Big Nerd Ranch.
]]>The post Introducing Freddy, an Open-Source Framework for Parsing JSON in Swift appeared first on Big Nerd Ranch.
]]>Parsing JSON can be tricky, but it shouldn’t be. We think parsing JSON should feel like writing regular Swift code.
That’s why we’re happy to introduce Freddy, a new open-source framework for parsing JSON in Swift 2. Freddy provides a native interface for parsing JSON.
In the battle of Freddy vs. JSON, who wins? We think it’s Freddy.
Who Needs Another JSON Framework?
There are already several JSON parsing solutions available in the Swift ecosystem, so why do Swift developers need another one?
In our survey of what was available, and in our own work, we were unsatisfied with the current options. Freddy is our solution, and seeks to:
- Maximize safety
- Be familiar using idiomatic style
- Provide speedy parsing
Freddy is Safe
The goal of Freddy is to transform JSON data into an instance of Freddy’s JSON type. JSON is an enumeration with a case for each data type described by the format.
public enum JSON {
case Array([JSON])
case Dictionary([Swift.String: JSON])
case Double(Swift.Double)
case Int(Swift.Int)
case String(Swift.String)
case Bool(Swift.Bool)
case Null
}
Each case has an associated value, with the exception of .Null. Because JSON data can have a nested structure, the cases for .Array and .Dictionary have associated values that contain further instances of JSON.
The benefit of this enumeration is that if you have an instance of JSON, then you know you have some data to examine in the case’s associated value (with exception of .Null).
Freddy exposes several methods for safely retrieving values from JSON’s cases.
Freddy is Idiomatic
Freddy’s API focuses on providing an approach to parsing JSON that feels right in Swift. That means there are no strange custom operators. The framework uses optionals when it makes sense, and it utilizes Swift’s mechanism for error handling to provide additional safety.
Freddy also uses the good practices established by the Swift community and the standard library. For example, Freddy uses protocols and extensions to make the code more readable and modular.
Users of Freddy should be able to read through the source code and easily understand its architecture. We also hope that our approach will make it easy for fans of the framework to contribute to its future.
Freddy is Fast
Our initial solution fed NSData to NSJSONSerialization.JSONObjectWithData(_:options:) and then recursively switched through the returned AnyObject to create an instance of JSON. We found that parsing JSON in this manner can be slow for large data payloads, largely due to switching over, and casting between, the various types encapsulated by the AnyObject instance.
So we wrote our own parser that natively emits an instance of JSON directly. Our parser is much faster than the alternative described above. Check out the Wiki page for benchmarks and more information.
Freddy in Action
Freddy’s README provides a good introduction to the framework, and Freddy’s Wiki offers a lot of great information and examples. Let’s take a look at an example to get started.
Sample JSON
Consider some sample JSON:
{
"messages": [
{
"content": "Here is some message.",
"read": false
},
{
"content": "More messages for you!",
"read": true
}
]
}
This JSON describes a user’s messages. The key "messages" has an array of dictionaries as its value. Each dictionary in the array is a message. For simplicity, a message just has two keys: one for content, and another for whether the message has been read.
Decoding JSON Instances
Now, let’s imagine that you want to parse this JSON into instances of a model type called Message. Here is how that type looks:
struct Message {
let content: String
let isRead: Bool
}
The question becomes: How do we decode the above JSON data into instances of Message? Freddy’s solution uses a protocol named JSONDecodable.
public protocool JSONDecodable {
init(json: JSON) throws
}
JSONDecodable requires conforming types to implement an initializer that takes an instance of JSON.
Message needs to implement this initializer.
extension Message: JSONDecodable {
public init(json: JSON) throws {
content = try json.string("content")
isRead = try json.bool("read")
}
}
Since parsing JSON can be error prone, we must try to find the String associated with the key "content". The same is also true for trying to find the Bool associated with the key "read". Either of these calls may generate an error, and so this initializer is marked with throws.
Creating JSON
We know that we need pass an instance of JSON to Message’s implementation of init(json:). But how do we do that? We need to create an instance of JSON.
let data: NSData = getSomeData() // E.g., from a web service
do {
let json = try JSON(data: data)
let messages = try json.array("messages").map(Message.init)
} catch {
// Handle errors
}
After we getSomeData()—a fictitious method that returns an instance of NSData—we can create an instance of JSON with its initializer: init(data:usingParser:). The second parameter, usingParser, has a default value that uses our custom JSONParser type. With json in hand, we can begin the work of finding our user’s messages.
The call json.array("messages") finds the array value for the key "messages" within the JSON instance. Essentially, we supply a path within the JSON—"messages"—and get out a new JSON instance representing what was found at the path. In this case, we get a JSON array of dictionaries.
Next, we chain a call to map(Message.init) on that array to apply the JSONDecodable initializer to each element. We pass each of the JSON dictionaries to init(json:). Message’s implementation will grab the relevant data and assign it to the content and isRead properties. If everything goes as planned, messages will be of type [Message]—an array of the user’s messages.
If everything does not go as planned, then you will get an error telling you what went wrong. This helps you to debug your JSON, and will increase your confidence in your program at runtime.
Another Way
The call json.array("messages").map(Message.init) may feel clunky to you. Good news! Freddy provides an easier way.
let data: NSData = getSomeData() // E.g., from a web service
do {
let json = try JSON(data: data)
let messages = try json.arrayOf("messages", type: Message.self)
} catch {
// Handle errors
}
Functionally, arrayOf(_:type:) behaves very similarly to what we saw above with array("messages").map(Message.init). The improvement here is that it does the same work (it produces an array of messages) with a more concise syntax.
Freddy in the Future
You can read more about the particulars of Freddy in the online documentation. We hope that our approach will make it easy for fans of the framework to contribute to its future.
The post Introducing Freddy, an Open-Source Framework for Parsing JSON in Swift appeared first on Big Nerd Ranch.
]]>The post Swift 2.0 Error Handling appeared first on Big Nerd Ranch.
]]>As my fellow Nerd Juan Pablo Claude pointed out in his post on Error Handling in Swift 2.0, the latest iteration of Swift introduces many features, and a new native error handling model is notable among these.
Prior to its 2.0 release, Swift did not provide a native mechanism for error handling. Errors were represented and propagated via the Foundation class NSError. In focusing on enumerations, the new model for error handling in Swift 2.0 feels more idiomatic.
While Juan Pablo’s post offered a bit of history and differences between Objective-C and Swift error handling, today I’d like to dive into the differences in error handling between Swift 1.2 and Swift 2.0.
Error Handling in Swift 1.x
In Swift 1.x, a reference to an NSError was passed to an NSErrorPointer parameter in a function or method to fill in error information if it exists.
And while NSError was serviceable, its strong emphasis on string error domains and integer error codes made it difficult to examine an error and know exactly what to do with it.
If you wrote any Swift 1.x code, then you might have written something like:
var theError: NSError?
func doSomethingThatMayCauseError(error: NSErrorPointer) -> Bool {
// do stuff...
var success = true
// if there is an error, then make the error, and set the return to `false`
if error != nil {
error.memory = NSError(domain: "SuperSpecialDomain", code: -99, userInfo: [
NSLocalizedDescriptionKey: "Everything is broken."
])
success = false
}
return success
}
let success = doSomethingThatMayCauseError(&theError)
if !success {
if let error = theError {
println(error.localizedDescription) // "Everything is broken."
}
}
As the example demonstrates, error handling in Swift 1.x was constrained by an intellectual debt to NSError. This constraint meant that code had to create an optional instance of NSError, and pass its pointer to some function that took an NSErrorPointer. That pointer was then later used in the function to fill it out with error information if there was a problem. If a non-nil pointer was indeed passed into the function’s error parameter, then an appropriate error was created and assigned to the NSErrorPointer’s memory property.
Since the function returned true on success, that was the first thing to check. If the return was false, then theError needed to be unwrapped because there was a problem. Examining the error would then give a little more information on what went wrong.
This process adds a lot of mental overhead. It adds boilerplate code (e.g., the optional binding syntax) and we even have to use a strange new type called NSErrorPointer. It is reliant upon an Objective-C class (NSError) and requires that we wrap a pointer to this class in a new type made just for Swift. NSError also forces us to use optionals, but we would obviously much prefer a more straightforward mechanism: Is there an error or not? It would be better to know decisively that there is an error, but the above code instead relies upon our interrogation of an NSError instance.
Last, NSError does not make it easy to represent and check error information exhaustively. There are many occasions where you may get an error back, but depending upon the domain and the code, you may not actually care about that particular error. Because NSError buries that information in its properties, you have to write code to make sure that the error you received is the one you are prepared to handle.
Error Handling in Swift 2.0
Swift’s new model for error handling is much more idiomatic. A new protocol called ErrorType represents a native mechanism for representing errors. ErrorType is designed to work specifically with enumerations. You create an enumeration to model the sorts of errors you expect to encounter. This means that you create error types that comprise a known set of some sort of error (more on this soon).
Error handling in Swift 2.0 takes advantage of Swift’s powerful enumerations. The associated values on an enum’s cases make it easy to pack additional error information into an instance of the enum. Furthermore, listing potential errors in the cases of an enum makes error handling more complete, predictable and exhaustive: You handle the errors you expect and can do something with.
An Example Database
Consider an example that seeks to build a naive database to house users and their movie ratings.
First, we have a Movie type.
struct Movie {
let name: String
}
Movies are simple; they just have a name.
Since Movie is a value type, let’s be sure to conform to Equatable; we will take advantage of this functionality later on.
extension Movie: Equatable {}
func ==(lhs: Movie, rhs: Movie) -> Bool {
return lhs.name == rhs.name
}
Movies can be rated with a Rating enum.
enum Rating {
case Bad, Okay, Good
}
Movies can be .Bad, .Okay and .Good.
Movies are rated by a User. Users just have names and emails. Again, because User is a value type, we will be sure to make User conform to Equatable.
struct User {
let name: String
let email: String
}
extension User: Equatable {}
func ==(lhs: User, rhs: User) -> Bool {
return lhs.name == rhs.name && lhs.email == rhs.email
}
User’s conformance to Equatable simply checks to see if the two instances have the same name and email.
A MovieRating type ties all of these together and will represent a table for movie ratings in our database.
struct MovieRating {
let rating: Rating
let rater: User
let movie: Movie
}
Instances of MovieRating have properties for ratings, raters and movies.
As above, we have MovieRating conform to Equatable.
extension MovieRating: Equatable {}
func == (lhs: MovieRating, rhs: MovieRating) -> Bool {
return lhs.rating == rhs.rating && lhs.rater == rhs.rater && lhs.movie == rhs.movie
}
We are almost ready to make our movie review database. Before we begin, it is worthwhile to consider our database’s API. Since Swift 2.0’s error handling model relies upon enumerations, it is easy to think about the sort of errors we may encounter while we are designing a type’s implmentation.
Let’s start out with this implementation of our database’s error type.
enum DatabaseError: ErrorType {
case InvalidUser(User)
case MoviePreviouslyRated(Movie)
case DuplicateEmailAddress(String)
}
The enum DatabaseError sketches out the sort of functionality that we can expect the database to perform by listing the possible errors we may expect from it. This helps to set our expectations for the database’s API. Just glancing at this enum tells us that queries to the database may involve an invalid user, something having to do with previously rated movies, and a duplicate email address.
Notice that the database’s error type is modeled as an enumeration.
This helps the error type to comprehensively list out all of the errors that we can expect from it. The enumeration tells us that it is modeling errors via its conformance to the ErrorType protocol. Since DatabaseError is a regular Swift enumeration, we can even add associated values to particular cases on the enum to give useful error information to an instance of DatabaseError.
Let’s implement our Database to see how this enum will be used.
class Database {
private(set) var users: [User] = []
private(set) var movies: [Movie] = []
private(set) var ratings: [MovieRating] = []
func createUser(withName name: String, email: String) throws -> User {
let userEmails = users.map { $0.email }
if userEmails.contains(email) {
throw DatabaseError.DuplicateEmailAddress(email)
}
let newUser = User(name: name, email: email)
users.append(newUser)
return newUser
}
}
The Database is a class with three stored properties.
One for the users in the database, another for the movies that users have rated, and a final property for movie ratings. For simplicity, these are stored properties with default values of empty arrays.
Creating Users
Database currently has only a single method—one for creating users and inserting them into the database. The method createUser has parameters for all of the inputs needed to create a user. After the parameter list, however, there is a new keyword being used: throws.
throws marks the method as potentially generating an error.
For example, it is possible that somebody will try to create a user with the exact same email address as another user (which this database uses to differentiate users). If this should happen, then the function throws an error. The error will tell the caller what went wrong.
In this case, the error will be .DuplicateEmailAddress and will carry with it the duplicated email address in the case’s associated value.
If no error is encountered, then the method will append the newUser to Database’s users array. Last, createUser will return the new user.
You might think that the createUser function has the following type: (String, Int, [Movie]) -> User. After all, that’s what the type would be in Swift 1.2. But this is Swift 2.0, and there is this weird throws keyword. As you now know, throws means that this method may generate an error. Indeed, throws tells the compiler that this function is different. It is so different that it has a different type: (String, Int, [Movie]) throws -> User.
Let’s create an instance of the Database to make a new user and see how error handling in Swift 2.0 works.
var db = Database()
do {
var alana = try db.createUser(withName: "Alana", email: "alana@example.com")
} catch DatabaseError.DuplicateEmailAddress(let email) {
print("(email) already exists in the database.")
} catch let unknownError {
print("(unknownError) is an unknown error.")
}
Since createUser can throw an error, we have to use a do-catch statement to capture and respond to errors.
Inside of the do block, we try to call a function that may throw an error. In this case, a call to createUser may succeed, but it also may fail. The reason that it may fail is if that new user is created with a duplicate email address.
This error is captured in the catch block, which looks and works like a switch statement. Here, we check to see if the error matches a specific case on the DatabaseError enum: .DuplicateEmailAddress. Since this case has an associated value, we can bind this value to a constant (email in this example), and use it to respond to the error. In the example above, all we do is log that invalid email to the console. A more “real-world” application might do something more meaningful like let the user of the application know that a particular email has already been taken.
Notice that the do-catch statement above is concluded with a “catch-all” block. This catch does not provide any pattern to match an error against, and so it will capture any error that comes through. It does specify a new local constant to bind this uncaught error to: unknownError. If this constant were not specified, then the compiler would have bound the error to a constant named error to be used locally within this catch. Similar to switch statements that must exhaustively address each potential case, Swift’s do-catch statements must exhaustively capture all possible errors.
The “catch-all” above works like a default case on a switch.
You might think that you can omit this “catch-all” by simply implementing a catch for each possible error. Unfortunately, Swift’s compiler cannot know that you are covering all errors in this manner. All the compiler knows is that you called a function that can throw an instance of some type that conforms to ErrorType. Thus, it cannot know all of the possible errors that could be encountered. This limitation is overcome by using a catch without an error pattern to match, which is called a “catch-all.”
(Incidentally, if you are following along in playground, the compiler will not require that you have this “catch-all.” However, a regular Xcode project will give you a compiler error telling you that you have not caught all possible errors if you omit the “catch-all”.)
Adding a Movie Rating
Now that alana is in the database, let’s give this user a movie rating.
Let’s first make an add method on the database.
func add(movie movie: Movie, withRating rating: Rating, forUser user: User) throws {
if !users.contains(user) {
throw DatabaseError.InvalidUser(user)
}
let userRatedMovies = ratings.filter { $0.rater == user }.map { $0.movie }
if userRatedMovies.contains(movie) {
throw DatabaseError.MoviePreviouslyRated(movie)
}
if !movies.contains(movie) {
movies.append(movie)
}
ratings.append(MovieRating(rating: rating, rater: user, movie: movie))
}
The method add takes a movie, a rating and a user as arguments. It throws an error should the user not exist in the database, or if the user previously rated the movie. Hence, this method can throw two potential errors.
If the user is valid and the movie has not been previously rated by that user, then the movie is added to the database’s ratings property. If the movie has not already been added to the database, we also add it to the array of movies in the database.
Now we can use the add method to give a movie rating to the database.
do {
var alana = try db.createUser(withName: "Alana", email: "alana@emaple.com")
let darko = Movie(name: "Donnie Darko")
try db.add(movie: darko, withRating: .Good, forUser: alana)
} catch DatabaseError.DuplicateEmailAddress(let email) {
print("(email) already exists in the database.")
} catch DatabaseError.InvalidUser(let user) {
print("(user) is not in the database.")
} catch DatabaseError.MoviePreviouslyRated(let movie) {
print("User has already rated (movie.name)")
} catch let unknownError {
print("(unknownError) is an unknown error.")
}
We create an instance of Movie, then attempt to add that movie to the database. Notice that we have added two new catches. These help to capture errors related to alana not being in the database and the movie Donnie Darko already being rated by alana.
The do-catch statement now does several things. It creates an instance of User, creates a Movie instance, and adds that instance to the database. The code above also catches all of the possible errors that may arise from these operations. Of course, a real app should do something more useful with these error than simply logging them to the console.
try, but do not try!
Any method that is marked with throws needs to be dealt with appropriately. Consider the following example:
func myFunc() throws { ... }
If you were to call myFunc (e.g., myFunc()), then the compiler will yell at you: Call can throw but is not marked with 'try'. Functions (and methods) that throw errors must be tried when called: try myFunc(). It is up to you to handle the errors correctly, but the compiler will require that you at least try.
In keeping with Swift’s emphasis on compile time safety, we can now mark functions as potentially throwing an error. This changes the type of the function, which differentiates a function that throws from a function that does not. Calling a function that throws means that you are required to try the function when you call it.
Swift 2.0 provides us with a mechanism to short circuit this safety if needed. In the code above, myFunc throws some sort of error. Calling myFunc without a try will lead to a compiler error. However, you can circumvent this requirement by using try!: try! myFunc(). This will prevent the error from being forwarded on to you. It essentially tells the compiler that you do not care about the potential errors that may arise from calling the function.
As you might expect, using try! is dangerous. The exclamation point (!) should stir within you the same fear and responsibility it does when forcibly unwrapping optionals. If there is an error, function call marked with try! will cause a runtime error, which will crash your application. You should only use try! when you are absolutely sure the call will not generate an error, or if you are absolutely sure you want to crash if there is an error. In either case, try! should be used sparingly and should require strong justification.
Final Thoughts
Swift 2.0’s model for error handling brings a native mechanism to handling errors. In brief, its use of enumerations allows for a do-catch statement that works similarly to a switch statement, and enumerations provide an elegant way to capture the errors that may be thrown. Functions marked with throws must be called with try. These functions should signal to you that you need to handle some error.
The post Swift 2.0 Error Handling appeared first on Big Nerd Ranch.
]]>In this demo, I cover Interactive Playgrounds and Functional Programming.
The post iOS 8 Demo: Interactive Playgrounds and Functional Programming appeared first on Big Nerd Ranch.
]]>In this demo, I cover Interactive Playgrounds and Functional Programming.
You can follow along with our iOS 8 demo repo, and my latest blog post discusses interactive playgrounds in more detail.
Can’t get enough info about iOS 8 and Swift? Join us for our Beginning iOS with Swift and Advanced iOS bootcamps.
The post iOS 8 Demo: Interactive Playgrounds and Functional Programming appeared first on Big Nerd Ranch.
]]>WWDC 2014 was full of surprises and exciting technology to explore, and the new Playground was high on that list. Playgrounds provide a convenient environment for rapidly developing and trying out code. Apple’s Balloons.playground demonstrates much of the power of the Playground: it can serve as both a document and as a REPL. The combination of the two means that a Playground is a fully interactive document.
The post iOS 8: Interactive Playgrounds appeared first on Big Nerd Ranch.
]]>WWDC 2014 was full of surprises and exciting technology to explore, and the new Playground was high on that list. Playgrounds provide a convenient environment for rapidly developing and trying out code. Apple’s Balloons.playground demonstrates much of the power of the Playground: it can serve as both a document and as a REPL. The combination of the two means that a Playground is a fully interactive document.
Given that Playgrounds are highly interactive, they are a wonderful vehicle for distributing code samples with instructive documentation. They can furthermore be used as an alternative medium for presentations. Consider a typical presentation: the presenter is giving a talk using whatever software she or he prefers, and then it is time to show off some code. Or, perhaps the presenter was asked a question that requires experimentation. In either scenario, the presentation is deferred momentarily in favor of Xcode. While this process is somewhat effective, it disturbs the flow of the presentation. Playgrounds provide us with a mechanism to experiment with and demonstrate code without ever leaving the presentation.
In this post, I will show you how to peek inside the .playground file to gain a sense of how a Playground is put together. Glancing at these internals will help you to create your own interactive document. At the end of this post, you will have created your own Playground featuring text and external resources, all the while taking advantage of the Playground's REPL.
A Peek Inside
Let’s begin by downloading Apple’s Balloons.playground. Go ahead and click on the link above. One you have it downloaded, move the file somewhere convenient.
Now that you have the file, right-click on the Balloons.playground file and select “Show Package Contents.” Doing so will reveal a number of files. Interestingly, what appeared to be a single file is actually made up of several others. It is this hidden organization that drives some of the subtle power delivered by a Playground. You should see something like the image below.
Notice that you have three types of files, and two directories. For files, you have: 1) contents.xcplayground, 2) a number of .swift files, and 3) a timeline.xctimeline. The first is a sort of manifest file that tells the Playground how to display and organize its content; I will discuss this file in greater detail in the next section. The second set of file types contains the actual Swift code that is executed in the Playground. Third, the timeline.xctimeline file describes the timeline feature displayed in the Assistant Editor.
For directories, the Balloons.playground file has “Documentation” and “Resources”. Clicking on this first folder reveals that it contains a number of .html files and one .css file. The “Documentation” folder holds all of the textual content of the Playground described as a series of web pages. The CSS file defines the Playground's styling of these pages. Finally, the “Resources” folder contains all of the external assets that the Playground uses to render the game’s content.
Now that you have seen the hidden secrets of the Swift Playground, let’s make our own interactive document.
An Interactive Presentation
As mentioned above, imagine that you are teaching a class on Swift. You would like to make a presentation on constants and variables, and would prefer that your presentation takes advantage of the Swift REPL. Good news! You can make your presentation right inside of Swift.
Create a new Playground called Interactive.playground. Save this file where you like. Next, right-click on Interactive.playground and select “Show Package Contents.” You will see two files of note: contents.xcplayground, and section-1.swift. Go ahead and open contents.xcplayground in your text editor of choice. You should see something similar to the image below.
As you can see, this is an XML file that acts as a manifest for the Playground; it describes the organization of the Playgrounds’s content. You will put your content inside the sections tag. Notice the code tag? This tag links to a file in the Playground that contains your Swift code. If you open the section-1.swift file, you should see the standard Playground boilerplate code:
import UIKit
var str = "Hello, playground"
Delete the contents of this file, and replace it with the following:
let myName = "YOUR NAME HERE"
// try to change myName; what happens?
var myAge = // your age here
// try to change myAge; what happens?
If you open the Playground, then you should see that the code has changed.
Adding Documentation
Recall that Balloons.playground had a directory called Documentation. The directory contained a number of .html files, and each of these files were linked against in the XML inside the contents.xcplayground file. Copy that organization by creating a new folder inside Interactive.playground called Documentation.
It is worth mentioning that each section of content in the Documentation directory describes a distinct web page, which is displayed in the Playground as a web view. There is a lot of room for creativity here.
Switch to the Documentation folder and add a new file called section0.html. Open this file, and copy and paste the following HTML to it.
<!DOCTYPE html>
<html lang="en">
<head>
<link rel="stylesheet" type="text/css" href="style.css" />
</head>
<body>
<h1>Constants and Variables</h1>
<p>
Swift is more explicit about the mutability of an instance than Objective-C. While ObjC's mutability is determined by the class the developer uses, Swift requires that mutability be declared when an instance of a type is created.
</p>
<p>
When you want a constant, you must use <code>let</code>. Use <code>let</code> when you don't want an instance's value to change. If you would like a variable, you must use <code>var</code>. <code>var</code> is used when you know that an instance will change at some point.
</p>
<p>
Notice that this means that mutability is more of a conscious decision. You decide what you want right when you make an instance. In Swift, mutability is no longer an artifact of which class you use. Thus, more careful thought is required.
</p>
<p>
It is our suggestion that you initially opt for a constant, an immutable instance. Your application will be easier to maintain, read, and develop for if it is very clear what values can change, and what values cannot.
</p>
</body>
</html>
Thus, section0.html gives a simple description of the role and use of constants and variables in Swift.
Formatting Documentation with CSS
section0.html links to a CSS file called style.css. This CSS file works just the same way that you would imagine: it defines the styling of the HTML pages in your Documentation directory. Go ahead and create a new file called style.css and add it to your Documentation directory. Open this file and add the code below.
body {
background-color: #d0e4fe;
margin: 10px 25px;
padding-bottom: 20px;
}
h1 {
color: gray;
text-align: left;
font-size: 22px;
}
p {
font-family: "Helvetica";
font-size: 18px;
}
This CSS file is a very basic description of your HTML page’s style in terms of margins, colors, fonts and text alignment. If you prefer more or less styling, change it to match your taste.
Mapping the Content
The last step entails teaching the Playground how to organize its content. You will use the contents.xcplayground file to complete this task. Open this file in a text editor and update it to match the listing below.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<playground version='3.0' sdk='iphonesimulator'>
<sections>
<documentation relative-path='section0.html'/>
<code source-file-name='section-1.swift'/>
</sections>
<timeline fileName='timeline.xctimeline'/>
</playground>
The XML inside this file remained largely the same. The only difference is that you have added a tag called documentation. As you can probably guess, the role of this tag is to specify the location of a .html file for the Playground. This HTML file describes the web page content for the first section of the Playground. Finally, the order of the elements within the sections tag determines the order in which they will appear in the Playground.
Make sure that you have saved all of your CSS and HTML files and that they are in the appropriate folders. If Xcode is open, go ahead and close it. Reopen Xcode, select Interactive.playground and you should see something like the image below.
Conclusion
Playgrounds are among the most exciting new tools for the Mac and iOS developer. They are a great resource for rapidly testing and developing solutions to a problem. The tight feedback loop between the Playground and the user can also serve other purposes.
For example, Playgrounds offer some pedagogical benefits as well. Done well, a Playground can be a presentation tool with a full Swift REPL inside of it. It is also feasible that entire lessons can be mapped out in a single, or collection of, Playgrounds. Each section of the Playground could describe a new concept or pattern, and then be followed by a section for writing Swift code.
It is worth mentioning that there is more to explore in Playgrounds. For example, I didn’t cover using the Resources folder. You can use this folder to expose a variety of assets to your Playground, as demonstrated in the Balloons.playground. I leave it as an exercise for the reader to experiment with this feature.
Playgrounds even have an API that you can explore. Type in import XCPlayground at the top of a Playground and command-click on XCPlayground to see what is available. Functions like XCPSetExecutionShouldContinueIndefinitely(_:) and XCPShowView(_:, view:) look particularly interesting. Check back here soon for another post exploring this API.
Can’t get enough info about iOS 8 and Swift? Join us for our Beginning iOS with Swift and Advanced iOS bootcamps.
The post iOS 8: Interactive Playgrounds appeared first on Big Nerd Ranch.
]]>The post Announcing our Swift and iOS 8 Roadshow appeared first on Big Nerd Ranch.
]]>Beginning in October, we are taking our classes on the road for a Swift and iOS 8 Roadshow. We’re offering a series of one-day classes in eight cities covering Swift and iOS 8, just for experienced iOS developers.

I’m excited to teach the opening classes in Atlanta. On Oct. 2, we’ll begin with the iOS 8 bootcamp, and on Oct. 3, we will follow up with the Swift bootcamp. I’m thrilled to be a part of this series that will help iOS developers stay on the cutting edge and get prepared for the future.
Swift One-Day Training
We have offered an introduction to Swift in our iOS and Cocoa bootcamps since shortly after Swift was announced, but if you want an intensive training focused on Swift development, this is your chance to take advantage of Swift’s unique opportunities. We’ll spend the day taking a tour of Swift’s features, getting comfortable with its syntax via numerous presentations and hands-on exercises.
In the Swift one-day class, you’ll get a series of talks that will demonstrate the similarities and differences between Swift and Objective-C, and how to to map the concepts you know and love in Objective-C to Swift. You’ll also learn about Swift’s features that distinguish it from Objective-C and help it to be a more powerful and modern language.
After the bootcamp, you’ll also be able to:
- Use and understand Swift’s basic types
- Declare and use variables and constants
- Leverage Swift’s control flows and looping constructs
- Create and use collections
- Know the power and use case of optionals
- Understand enums, structs and classes, and how to use them
- Develop and use simple to more nuanced functions
- Create closures and effectively use them
- Understand Swift’s new initializer pattern
- Work effectively with properties
- Implement Swift’s functional patterns
- Utilize extensions to enhance Swift’s “out-of-the-box” functionality
- Create and conform to protocols to develop a blueprint of functionality
- Create generics to increase your code’s flexibility and power
Development to the Power of 8
In our iOS 8 one-day bootcamp, you will learn the latest features introduced with iOS 8 and Xcode 6. We’ll show you how to master the biggest iOS release ever, and how iOS 8’s extensibility and adaptability improve the development experience.
We will cover the latest tools, techniques and frameworks, from changes to View Controller architecture to debugging, frameworks and extensions.
You’ll also learn how to:
- Use the latest layout and debugging features in Xcode 6
- Build embedded frameworks to modularize application development
- Let your app share content to a web service on behalf of other apps
- Put a widget in the Notification Center to highlight your content
- Use iCloud as a cloud backend for your app
- Transfer work-in-progress between an iOS and Mac app
- Present and use the new document picker for opening files from other apps
Move Swiftly
Ready to claim your spot? Register now before seats are filled. Starting today, we’re offering a three-day early enrollment window to our bootcamp alumni. Signups will open to the general public on Monday, Aug. 18. Each one-day bootcamp lasts from 8 a.m. – 5 p.m., with lunch and snacks provided.
And if you’re just getting started with iOS development, we’ve got you covered. Just register for our Beginning iOS bootcamp. You’ll learn the Swift language and how to use it to interact with the frameworks we cover throughout the week.
The post Announcing our Swift and iOS 8 Roadshow appeared first on Big Nerd Ranch.
]]>