

Swift Regex Deep Dive
iOS MacOur introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.
One of our interns recently asked what seemed like a fairly innocuous question: “What are the scenarios where the use of instance variables would be more preferred than using properties?” At Big Nerd Ranch, we strongly prefer using properties to direct ivar access, but take a sampling of the Objective-C community and you’ll find almost as many answers as there are developers:
“I always use properties and always access via properties (except when ivar access is strictly required).”
“I strongly prefer properties unless there is a very good reason to use ivars.”
“I generally prefer properties but will occasionally use ivars for simple state variables where the overhead of a property is unnecessary.”
“I use properties for ‘public’ things and ivars for ‘private’ things.”
“I often change ‘self.value’ calls to ‘_value’ because it’s much faster.”
Using properties has some very tangible benefits, particularly when it comes to debugging: they provide a single place to set a breakpoint on access or change, they can be overridden to add logging or other functionality, etc. Many of the answers that give some preference for ivars express concerns about the performance overhead of properties. We believe that the overhead is insignificant for most applications, but thought it would be fun to prove it. Is it possible to create a pathological app where you can actually see the difference? (Yes.) Just how much overhead is there in the message send used for setting and getting a property? (Hint: it’s measured in nanoseconds.)
 PropertyPerformance project on Github
PropertyPerformance project on Github
We don’t need to get very elaborate to come up with a test that stresses properties. The app performs a meaningless but expensive computation and calls setNeedsDisplay as quickly as possible, up to the limit of how quickly iOS will redraw the display (120 frames per second). The computation is a for loop that performs floating point additions, so we can easily scale how expensive it is by adjusting the number of iterations in the for loop.
To start, let’s investigate two different loops: one that accesses a property via the default getter and one that accesses an ivar directly.
// Inner loop using properties.
for (NSUInteger i = 0; i < loopSize; i++) {
x += self.propertyValue;
}
// Inner loop using instance variables.
for (NSUInteger i = 0; i < loopSize; i++) {
x += _ivarValue;
}
The following chart plots the performance of the app in frames per second on an iPhone 5:
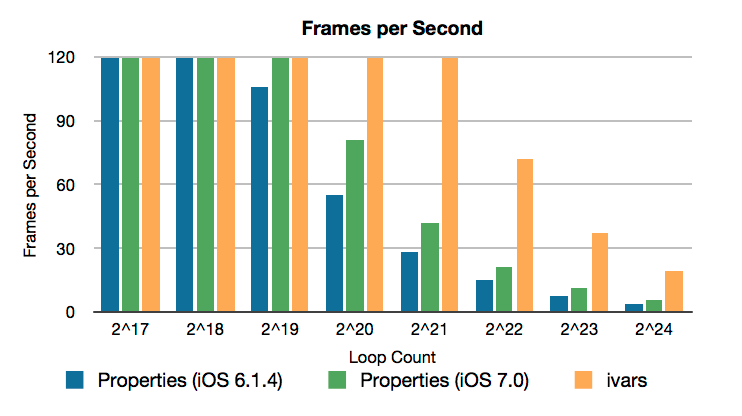 At large loop sizes, the property version of the for loop is about five times slower than the ivar version in iOS 6 and about 3.5 times slower in iOS 7. Let’s look at the disassembly to see why. First, the property version:
At large loop sizes, the property version of the for loop is about five times slower than the ivar version in iOS 6 and about 3.5 times slower in iOS 7. Let’s look at the disassembly to see why. First, the property version:
; Inner loop using properties.
0xc4a7a: mov r0, r11 ; move address of "self" into r0
0xc4a7c: mov r1, r6 ; move getter method name into r1
0xc4a7e: blx 0xc6fc0 ; call objc_msgSend(self, getterName)
0xc4a82: vmov d16, r0, r0 ; move the result of the getter into d16
0xc4a86: subs r5, #1 ; subtract 1 from our loop counter
0xc4a88: vadd.f32 d9, d9, d16 ; add d9 and d16 and store result into d16
0xc4a8c: bne 0xc4a7a ; repeat unless our loop counter is now 0
Every time through the loop, we have to call objc_msgSend to call the property’s getter, move that result into the d16 register, and then perform the actual addition via vadd.f32, a NEON instruction (more on that later). This disassembly did not change between the runs on iOS 6 and iOS 7, strongly suggesting that Apple sped up objc_msgSend, which by all accounts was already quite fast. This also lends even more weight to the performance mantra of “profile, don’t guess”—performance issues can change dramatically between different pieces of hardware (probably obvious) and between iOS updates even on the same hardware (perhaps less obvious).
On to the ivar version:
; Inner loop using instance variables.
0xc4aba: vadd.f32 d9, d9, d0 ; add d9 and d0 and store result into d9
0xc4abe: subs r0, #1 ; subtract 1 from our loop counter
0xc4ac0: bne 0xc4aba ; repeat unless our loop counter is now 0
In the ivar case, the compiler loads the current value of the ivar into the d0 register before entering the loop. It might come as a surprise that the compiler makes the assumption that the value of the ivar will not change while the loop is running. The short answer is that because the ivar is not declared as volatile, the compiler is free to “assume its value cannot be modified in unexpected ways”; for more details, see Compiler Optimization and the volatile Keyword at the ARM website.
This pathological app is a lot of fun to play with, but it isn’t particularly accurate, since it’s tied to redrawing the display and all the myriad things associated with that. If we abandon the UI and focus on timing properties, we can get some pretty good information. As with any timing information, there are a lot of caveats: measurements were taken on an iPhone 5 running iOS 7.0, and we were reading a single 32-bit float that was already in the L1 cache. Under these circumstances, reading directly via the ivar takes about 3 nanoseconds, and reading via the getter takes about 11 nanoseconds.
Are there apps that need to be concerned with performance differences measured in single-digit nanoseconds? Sure. But do most? No way. Consider this method call, which everyone will recognize:
[self.navigationController pushViewController:self.someOtherViewController animated:YES];
Is it slower to use self.someOtherViewController instead of _someOtherViewController? Yeah, by about 8 nanoseconds. Using some tricks Mark D talked about with DTrace, we can provide some context. On iOS 7.0, that single line of code results in more than 800 calls to objc_msgSend, and by the time the other view controller has actually appeared on screen, the count jumps to more than 150,000. Think about that: counting objc_msgSend time alone, that single property access costs 1/800th of what it costs just to kick off the presentation of the view controller. It’s practically free, and because of that, the consistency of the code offered by using property accessors wins out. It’s time to stop worrying and embrace properties.
Because it’s not really germane to the original question, we haven’t talked much about the actual addition happening in the inner loops of the sample app. The assembly instruction vadd.f32 is a NEON instruction. It takes two 64-bit NEON registers, treats them as each holding two 32-bit floating point numbers (in their top and bottom 32 bits), and performs two 32-bit additions simultaneously, storying the two 32-bit results into the top and bottom halves of a third 64-bit NEON register. However, in all the compiler-generated loops we’ve seen so far, we’re only performing a single addition in each iteration of the for loop—the other half of the vadd.f32 operation is being discarded at the end of the loop, so we’re wasting half our potential performance!
We can write a NEON-enabled version of the loop using the functions found in the arm_neon.h header. Be warned that blindly including this file and using the functions it declares will leave your app unable to run on both the simulator and older hardware that doesn’t support the NEON instruction set. Here is a version of the for loop that uses 64-bit NEON intrinsics:
{
// A float32x2_t corresponds to a 64-bit NEON register we treat as having
// two 32-bit floats in each half. vmov_n_f32() initializes both halves
// to the same value - 0.0f, in this case.
float32x2_t x_pair = vmov_n_f32(0.0f);
// Note that we now increment by 2 since we're doing two adds on each pass.
for (NSUInteger i = 0; i < loopSize; i += 2) {
// Construct a pair of 32-bit floats, both initialized to our ivar.
float32x2_t pair = vmov_n_f32(_value);
// Perform vadd.f32
x_pair = vadd_f32(x_pair, pair);
}
// To get our final result, we need to extract both halves, or lanes, of
// our accumulator, and add them together, storing the result in the
// CGFloat x.
x = vget_lane_f32(x_pair, 0) + vget_lane_f32(x_pair, 1);
}
But we don’t have to stop there—the NEON instructions also allow us to use 128-bit wide registers that hold four 32-bit floats each; see NEON registers for how all these different levels of registers are overlaid on top of each other. Here is a version of the for loop that uses 128-bit NEON intrinsics. The strategy and logic is the same as the 64-bit version, except we get four floats per variable instead of two:
{
float32x4_t x_quad = vmovq_n_f32(0.0f);
for (NSUInteger i = 0; i < loopSize; i += 4) {
float32x4_t quad = vmovq_n_f32(_property);
x_quad = vaddq_f32(x_quad, quad);
}
x = vgetq_lane_f32(x_quad, 0);
x += vgetq_lane_f32(x_quad, 1);
x += vgetq_lane_f32(x_quad, 2);
x += vgetq_lane_f32(x_quad, 3);
}
How do these NEON versions compare? The 64-bit NEON version is about twice as fast as the normal ivar version, and the 128-bit NEON version is about four times as fast as the normal ivar version:
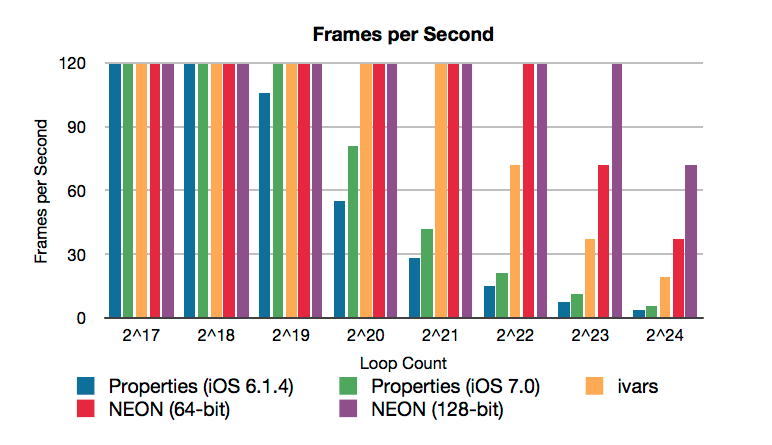
There is a tremendous amount of power tucked away in NEON. Most applications will never need it, but it’s nice to know it’s there.
Our introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.

The Combine framework in Swift is a powerful declarative API for the asynchronous processing of values over time. It takes full advantage of Swift...

SwiftUI has changed a great many things about how developers create applications for iOS, and not just in the way we lay out our...