
The post Slide Design for Developers appeared first on Big Nerd Ranch.
]]>
At RubyConf last week, I had a great time listening to interesting talks and chatting with fellow Rubyists, and I even made it out to the beach a few times. It was also my first time presenting at a conference.
My talk, titled “Raft: Consensus for Rubyists,” went really well and I got some great feedback from the audience. While the subject of the talk could be a blog post entirely on its own, I wanted to answer some questions about one particular part of the presentation: the slide deck. Here are a few tips on slide design for developers.
Small content, huge text
The smallest font size I would recommend is 64 pt. This really helps in two ways. The audience can actually read your slides, even from the back of the room. It also forces you to limit the number of words on each of your slides.
Do you have a slide with a paragraph of text on it? Try to summarize it in six words or fewer. Are you showing multiple questions and answers per slide? Break them up and show only one question and answer per slide. I’ve even gone as far as having a single word at 400 pt in order to really get an idea across.
The more slides, the better
Splitting up slides means you’ll have many more slides for the same amount of content. But changing slides more often can help keep the audience’s attention. You can see this in modern film as well. The current average shot length, or time between cuts in a film, is generally 5-15 seconds. So try applying that to your next presentation. If you’re giving a 30-minute presentation, you might consider going through 120 slides, or one every 15 seconds.
That doesn’t mean you have to discuss a different idea on each slide. Instead, try moving through a few slides with relevant phrases on each while explaining a single topic. This works especially well when explaining diagrams. Don’t display the entire diagram initially. You can slowly add relevant parts on each slide as you explain them.
Transition with color
Most presentations have topics or ideas that can easily be split up into groups. To help the audience more easily group the content together, use similar colors for similar themes. For example, if you were explaining the pros and cons of different programming languages, you could use red as the background color for the slides about Ruby and blue for slides about Objective-C. I also tend to use a contrasting color scheme for important questions, so the audience knows that this is something they need to remember.
If you’re like me and have trouble knowing what colors look good together, try finding a popular color palette on ColourLovers or Kuler. Another simple improvement you can make is to never use black or white, and instead use a dark grey or very light grey, since it’s easier on the eyes.
Tools I use
I currently stick to Keynote for designing my slides. The new Mavericks release is pretty nice and made it a lot easier to quickly change colors and other element attributes. I usually try to use their grid snapping to align everything, and I spend extra time using the shape tools to get my diagrams just right. Sometimes I’ll also take screenshots for a slide or two by hitting command + control + shift + 4 and then the space bar to take a full application window shot.
Once you’re done with your presentation and want to share it, check out SpeakerDeck. All you need to do is open up Keynote, hit File -> Export To -> PDF… and make sure you use the “Best quality” option to get a PDF of your slides, which you can upload straight to SpeakerDeck.
Good luck with your next presentation. Hope these tips help you put together some great slides. If you have any other good tips or want to share your favorite slide deck, post it below in the comments.
The post Slide Design for Developers appeared first on Big Nerd Ranch.
]]>Have you recently used a Twitter, Facebook or Google API? If so, you probably authenticated with OAuth2. Instead of using their own authentication schemes, most new services choose to implement OAuth2, the latest revision of the OAuth protocol. It gives your users a secure way to talk to your service, but more importantly, allows users to safely authorize access to their data from third-party services without giving them their credentials. Let’s build a sample server implementation in Ruby and see how it all works.
The post OAuth2 and So Can You appeared first on Big Nerd Ranch.
]]>Have you recently used a Twitter, Facebook or Google API? If so, you probably authenticated with OAuth2. Instead of using their own authentication schemes, most new services choose to implement OAuth2, the latest revision of the OAuth protocol. It gives your users a secure way to talk to your service, but more importantly, allows users to safely authorize access to their data from third-party services without giving them their credentials. Let’s build a sample server implementation in Ruby and see how it all works.
Here’s What We’re Going to Build
Since there are a few moving pieces, take a look at this graph of the typical flow of authentication:
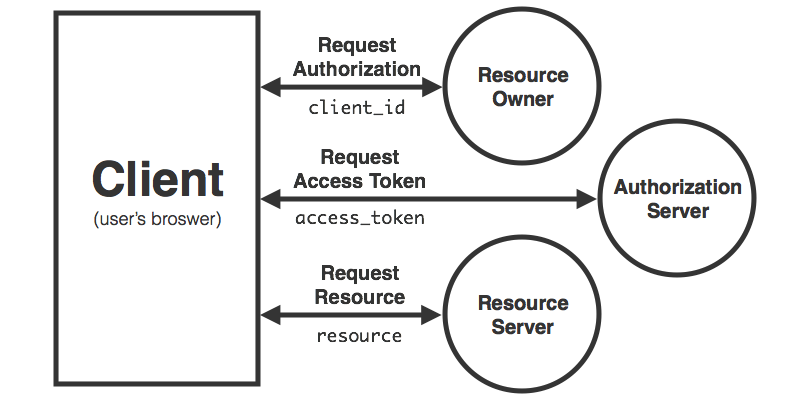
We start off asking the Resource owner to authorize our request, something like the ability to post tweets on their behalf. The user would then accept our request by clicking a link that would redirect them to Twitter and allow them to enter their credentials. Once Twitter confirms the credentials, it redirects the user back to our service including an access token. We can then use this access token to take the action we had previous asked the user about. The advantages here are that the user never gave us their credentials directly, only granted us a specific scope in which to operate, and still has the ability to revoke our access without changing their credentials or affecting other authorized services. Ok that was a lot of explaining. Let’s take a look at some code.
Let’s Cowboy Out Some OAuth
So you want to be able to authorize requests just like Twitter? Let’s go ahead and generate a new rails app and create an OAuthController. While it’s not the best design, to keep things simple we’re going to do most of the work right in the controller. We can start off by allowing users to register their application with with an application action. This action will represent the Resource Owner portion of the diagram above.
First we’ll need to create an Application class to hold on to the client_id.
class Application < ActiveRecord::Base
has_many :authorizations
before_save :generate_client_id
def generate_client_id
self.client_id = SecureRandom.hex(32)
end
end
Now we can just create one of these in the matching controller action (we’ll add routes for all of these at the end).
def application
respond_with Application.create
end
Ok now we’re on to the important part. We need to find the registered application by client_id and send the access_token back to the requesting application. This action will act as the Authorization Server from the diagram above. But remember this isn’t an API call, we have to redirect back.
So let’s create another model to hold the access_token we generate.
class Authorization < ActiveRecord::Base
belongs_to :application
before_save :generate_access_token
def generate_access_token
self.access_token = SecureRandom.hex(32)
end
end
Now we just need to redirect back to the original url with the access token.
def authorization
client_id = params[:client_id]
request_uri = params[:request_uri]
application = Application.find_by(client_id: client_id)
authorization = application.authorizations.create
access_token = authorization.access_token
redirect_to "#{request_uri}?access_token=#{access_token}"
end
Now for the final touches, wiring up the routes to controller actions.
post '/applications' => 'oauth#application'
get '/authorization' => 'oauth#authorization'
So let’s review how we can use these routes. First we register our application by posting to /applications. In the response we can find the client_id parameter used to generate an access_token. To authorize a user we need to redirect them to /authorization?client_id=… where the application will allow for its own authorization step and then redirect back to the request_uri along with the newly generated access_token.
But what about authorizing requests from a client other than a browser? All we need to do is add another way to generate an access_token. Typically this means using HTTP Basic Authentication with the credentials of the user. While this doesn’t give us the advantage of keeping our credentials from the client application, at least they are only used once after which we can revoke access independently.
There’s Still More to Be Done
Keep in mind we didn’t cover many pieces of OAuth2 that would be present in a typical production implementation. To implement a full provider we would need more in-depth attributes for applications, knowledge of scope parameters as they related to our application, more robust redirection allowing for multiple query parameters, and better security by validating a client secret and supporting refresh tokens. For a great example check out GitHub’s implementation of OAuth2. Also, there are some great implementations already written like this Rack app and Rails engine.
In the next episode we’ll cover how to use OAuth2 from an iOS app.
The post OAuth2 and So Can You appeared first on Big Nerd Ranch.
]]>Until recently, browsers really only supported stateless communication over HTTP. That’s beginning to change with new technologies like WebSockets and ServerSentEvents, but WebRTC throws a new feature into the mix: peer-to-peer communication. You can stream data directly between two browsers without having to connect through a server. Now backed by Google and Mozilla (Microsoft supports part of the spec), the project is gaining a lot of traction.
The post Making connections with WebRTC appeared first on Big Nerd Ranch.
]]>Until recently, browsers really only supported stateless communication over HTTP. That’s beginning to change with new technologies like WebSockets and ServerSentEvents, but WebRTC throws a new feature into the mix: peer-to-peer communication. You can stream data directly between two browsers without having to connect through a server. Now backed by Google and Mozilla (Microsoft supports part of the spec), the project is gaining a lot of traction.
Let’s take a look at some of the features and how to use them. The following examples use the webkit prefix for simplicity, but in most cases, switching to the moz prefix will work for Mozilla browsers.
Media Streams
By calling getUserMedia() the browser can ask for access (with approval from the user) to video and audio devices. Each device is returned as a MediaStream object, which acts just like a Blob from the FileReader API. We can then use a video tag and the return value of createObjectURL() as the source to display the live feed from our video camera and microphone. Here’s a tiny demo and a code snippet to emphasize how easy it is to use.
function onUserMediaSuccess(stream) {
video.src = URL.createObjectURL(stream)
}
function onUserMediaError(stream) {
console.log('Oops something went wrong!')
}
navigator.webkitGetUserMedia(
{ audio: true, video: true },
onUserMediaSuccess,
onUserMediaError
)
Peer Connections
Connecting to other computers can be a little tricky, especially if both clients are behind a router. To make this easier, ICE support is baked right in. Each browser can ask for a list of publicly accessible addresses (“candidates” is the domain term) which is then sent up to the server. When the other client receives the list from the server, they can then figure out which address works the best for opening a connection.
The connection process is pretty simple. Each client makes an offer to connect, which can include constraints and options like requiring a video stream. Then they will have a chance to accept or reject the offer. Once the connection is opened you can apply a stream (video and/or audio) which will forward any data received over the wire to the other browser. This keeps the API relatively simple, while still allowing the realtime communication that we need.
Since there are a few steps involved, let’s take a look at how we would implement this:
This example leaves out the communication with the server via ServerSentEvents (server.send() and server.onmessage()). A working implementation is up on GitHub if you’re interested.
connection = nil
server = new ServerConnection()
// Handle messages received from the server
server.onmessage = function(message) {
message = JSON.parse(message)
switch(message.type) {
// Respond to an offer
case 'offer':
connection.setRemoteDescription(new RTCSessionDescription(message))
connection.createAnswer(function(sessionDescription) {
connection.setLocalDescription(sessionDescription)
server.send(sessionDescription)
})
break
// Respond to an answer
case 'answer':
connection.setRemoteDescription(new RTCSessionDescription(message))
break
// Respond to an ice candidate
case 'candidate':
connection.addIceCandidate(new RTCIceCandidate({
sdpMLineIndex: message.label,
candidate: message.candidate
}))
break
}
}
// Create the connection object
connection = new webkitRTCPeerConnection({
iceServers: [{ url: 'stun:stun.l.google.com:19302' }]
})
// Try out new ice candidates
connection.onicecandidate = function(event) {
if(event.candidate) {
server.send({
type: 'candidate',
label: event.candidate.spdMLineIndex,
id: event.candidate.sdpMid,
candidate: event.candidate.candidate
})
}
}
// Wire up the video stream once we get it
connection.onaddstream = function(event) {
video.src = URL.createObjectURL(event.stream)
}
// Kick off the negotiation with an offer request
function openConnection() {
connection.createOffer(function(sessionDescription) {
connection.setLocalDescription(sessionDescription)
server.send(sessionDescription)
})
}
function onUserMediaSuccess(stream) {
connection.addStream(stream)
openConnection()
}
// Ask for access to the video and audio devices
navigator.webkitGetUserMedia({
audio: true,
video: true
}, onUserMediaSuccess, null)
Browser Support
Right now the project is still only available in developer builds of Chrome and Firefox. But since the specification has been at least partially implemented in more than one browser, it won’t be long until we see support for this in stable releases. Microsoft has begun implementing WebRTC for Internet Explorer, which is good news. However, there are a few places where they deviated from the W3C spec in favor of their own API. This might not be that big of a deal, since the crazy smart guys at Google added WebRTC support to ChromeFrame. I haven’t tried it myself, but supposedly it works in IE6.
There are even more WebRTC features that I haven’t even touched on in this post, like encryption, screen sharing and raw data connections. Check out the official specification, Google’s sample application, and start writing some apps of your own!
The post Making connections with WebRTC appeared first on Big Nerd Ranch.
]]>There were some great talks at RubyConf this year, covering themes like concurrency, monitoring and architecture, among others. But there were also a number of presentations about the future of Ruby, which piece together an interesting dialog.
The post The Future of Ruby: a RubyConf Recap appeared first on Big Nerd Ranch.
]]>There were some great talks at RubyConf this year, covering themes like concurrency, monitoring and architecture, among others. But there were also a number of presentations about the future of Ruby, which piece together an interesting dialog.
Ruby 2.0
Starting out with the very first presentation, Matz’s keynote took a quick look at the history of Ruby and his motivations for creating the language. He then dove right in to some of the exciting things he has been working on for Ruby 2.0. New language features like keyword arguments, Module#prepend, refinements and various speed improvements are just some of the things to look forward to in the upcoming release.
Shortly after Matz’s talk, Koichi Sasada gave an in-depth overview of his work on the Ruby 2.0 VM and how he has drastically improved the performance of method dispatch. Koichi also made a point to show us how much complexity already exists under the hood by giving a few “quiz” questions during his slides.
A different picture of the future
Next I decided to check out Brian Ford’s talk titled, “Toward a Design for Ruby.” At this point, I was pretty excited about all the new features I had been introduced to throughout the morning. However, this talk painted a different picture of Ruby’s future.
The talk was a criticism of Ruby. With Matz present in the audience, Brian did an excellent job of fairly addressing issues with communication, growing complexity of features (especially those expected to be released in Ruby 2.0), the state of the standard library and the need for specification of Ruby’s features.
Brian finished by saying, “Ruby is now over 18 years old. Please set it free to fulfill its destiny.” It was hard to hear that Ruby has significant challenges in its future, but I think it was a very healthy criticism that needed to be brought to everyone’s attention.
Matz addressed some of these concerns in his question-and-answer session, saying that improving communication with the Rubinius and JRuby teams is important to him and something they need to do. But there are still some very important questions that went unanswered:
-
Why doesn’t the core team use GitHub to develop MRI?
-
Why aren’t major discussions available in English?
-
Why don’t we have tests that define language features instead of implementation details?
-
Why do we still not have real concurrency in Ruby?
avoiding Community fragmentation
I’ve been thinking a lot about the quote, “Those who make collaboration impossible make forking inevitable.” Since I’m not a language implementer, I don’t frequently deal with these problems. The people who do, the people trying to improve Ruby, are the ones we need to worry about. If super-smart people who love Ruby, like Brian Ford, have no power to design and improve the language, they are either going to fix it themselves in their own implementation, or they are going to leave for another community that gives them that power.
I don’t want to see the community fragmented and I don’t want the awesome people supporting us to leave for another language. Let’s make sure that Ruby and the community stick around by taking these issues seriously and making projects like RubySpec and Rubinius first-class citizens.
The post The Future of Ruby: a RubyConf Recap appeared first on Big Nerd Ranch.
]]>
The post Upload Directly to Amazon S3 with Support for CORS appeared first on Big Nerd Ranch.
]]>
Our clients increasingly need features that rely on file uploads. In the past, we would typically use your average multi-part form with a file input and post the data to our servers. Once the file was done uploading, we would then turn around and push it to a cloud storage service.
But if you’re using Amazon Simple Storage Service (S3) to store your uploaded files, you can now upload files directly to Amazon without even touching your servers, speeding up your app in the process.
A couple of weeks ago, Amazon finally announced that S3 will now support Cross-Origin Resource Sharing (CORS). If you previously tried to be smart and post directly to your-bucket.amazons3.com with AJAX, you probably noticed an annoying “Origin not allowed” JavaScript error. Support for CORS fixes the problem by allowing you to specify which domains are allowed to communicate directly with your S3 bucket.
Add it to your app:
First, you’ll need to specify the domains and actions that you want to allow, since only GET requests are turned on by default. Log in to the S3 Console and select the bucket you want to use. Then click on “Properties” and then on the “Add CORS Configuration” button.

Then specify the actions you want. In this simple example, we just need GET and POST requests.
| <CORSConfiguration> | |
| <CORSRule> | |
| <AllowedOrigin>https://yourdomain.com</AllowedOrigin> | |
| <AllowedMethod>GET</AllowedMethod> | |
| <AllowedMethod>POST</AllowedMethod> | |
| <AllowedHeader>*</AllowedHeader> | |
| </CORSRule> | |
| </CORSConfiguration> |
In our app, we will need to send a signature to S3 along with any metadata or access control parameters. Here’s some Ruby code to help you out:
| def signature(options = {}) | |
| Base64.encode64( | |
| OpenSSL::HMAC.digest( | |
| OpenSSL::Digest::Digest.new('sha1'), | |
| SECRET_ACCESS_KEY, | |
| policy({ secret_access_key: SECRET_ACCESS_KEY }) | |
| ) | |
| ).gsub(/\n/, '') | |
| end | |
| def policy(options = {}) | |
| Base64.encode64( | |
| { | |
| expiration: 30.minutes.from_now.utc.strftime('%Y-%m-%dT%H:%M:%S.000Z'), | |
| conditions: [ | |
| { bucket: BUCKET }, | |
| { acl: 'public-read' }, | |
| { success_action_status: '201' }, | |
| ['starts-with', '$key', ''] | |
| ] | |
| }.to_json | |
| ).gsub(/\n|\r/, '') | |
| end |
Now let’s use the jQuery File Upload Plugin and put it all together to upload the files with AJAX:
| <!DOCTYPE html> | |
| <html> | |
| <head> | |
| <script type="text/javascript" src="/javascript/jquery.js"></script> | |
| <script type="text/javascript" src="/javascript/jquery.fileupload.js"></script> | |
| <script type="text/javascript"> | |
| $(function() { | |
| $('#fileupload').fileupload({ | |
| url: 'https://<%= BUCKET %>.s3.amazonaws.com/', | |
| type: 'POST', | |
| autoUpload: true, | |
| formData: { | |
| key: "<%= "#{SecureRandom.uuid}/${filename}" %>", | |
| AWSAccessKeyId: "<%= ACCESS_KEY_ID %>", | |
| acl: "public-read", | |
| policy: "<%= policy %>", | |
| signature: "<%= signature %>", | |
| success_action_status: "201" | |
| } | |
| }); | |
| }); | |
| </script> | |
| </head> | |
| <body> | |
| <form action="/upload" method="post" enctype="multipart/form-data"> | |
| <input type="file" id="fileupload" name="file"> | |
| <input type="submit" value="Save"> | |
| </form> | |
| </body> | |
| </html> |
This should securely upload a file and return a hash containing the exact file location.
Then you can just throw the location returned from S3 into a hidden field and submit the form to your server. Say goodbye to tying up processes with file uploads; now you can scale up to as many uploads as Amazon can handle.
Image credit: ahisgett
The post Upload Directly to Amazon S3 with Support for CORS appeared first on Big Nerd Ranch.
]]>As the web continues to mature, JSON APIs (and XML if you’re into that) have become increasingly important. But if you’ve tried to use Rails to write an API recently, you know there are a handful of competing methods and gems focused on making this better. I’m all for interchangable libraries, but, as Yehuda Katz pointed out in his recent talk at RailsConf, Rails needs a “convention over configuration” approach to solving the JSON serialization problem once and for all. So I was pretty excited when I heard about Jose Valim’s ActiveModel::Serializer.
The post Rails Needs to Make JSON Serialization Easier appeared first on Big Nerd Ranch.
]]>As the web continues to mature, JSON APIs (and XML if you’re into that) have become increasingly important. But if you’ve tried to use Rails to write an API recently, you know there are a handful of competing methods and gems focused on making this better. I’m all for interchangable libraries, but, as Yehuda Katz pointed out in his recent talk at RailsConf, Rails needs a “convention over configuration” approach to solving the JSON serialization problem once and for all. So I was pretty excited when I heard about Jose Valim’s ActiveModel::Serializer.
Instead of dealing with JSON views or presenters, ActiveModel::Serializer adds a new layer between rendering JSON in a controller and defining a custom to_json method. Now when rendering JSON in a controller Rails will look for a Serializer for the matching model and defer to that for generating the payload. Here are some examples to get you up and running.
We can start with a really simple Cat model.
| class Cat < ActiveRecord::Base | |
| attr_accessible :name, :mood, :owner_id | |
| has_one :owner | |
| end |
Now lets write a controller action. Not really anything exciting yet.
| class CatsController < ApplicationController | |
| respond_to :json | |
| def index | |
| respond_with Cat.all | |
| end | |
| end |
OK so here’s where the magic happens. Let’s say we want to change up the JSON a little bit. For example we want to include the owner’s attributes as well. Well that’s super easy. Just make a CatSerializer in app/serializers like this.
| class CatSerializer < ApplicationSerializer | |
| attributes :id, :name, :mood | |
| has_one :owner | |
| end |
Now look how our JSON response has changed!
| /* Standard */ | |
| [ | |
| { | |
| "id": 1, | |
| "name": "Felix", | |
| "mood": "crazy" | |
| }, | |
| { | |
| "id": 2, | |
| "name": "Gorbachev", | |
| "mood": "awesome" | |
| } | |
| ] | |
| /* With a Custom Serializer */ | |
| { | |
| "cats": [ | |
| { | |
| "id": 1, | |
| "name": "Felix", | |
| "mood": "crazy", | |
| "owner": { "id": 5, "name": "Pat Sullivan" } | |
| }, | |
| { | |
| "id": 2, | |
| "name": "Gorbachev", | |
| "mood": "awesome", | |
| "owner": { "id": 6, "name": "Aaron Patterson" } | |
| } | |
| ] | |
| } |
This isn’t a very radical change in how some of the other decorator gems work, but I think it does a really good job at making serialization a first class citizen. Also the fact that it was built by 2 Rails core members probably gives it the best chance for some day being included in all Rails apps be default. Now they just need to convince DHH that it’s a better approach than using JSON views with Jbuilder. 😛
The post Rails Needs to Make JSON Serialization Easier appeared first on Big Nerd Ranch.
]]>Hadoop is a great solution to the big data problem and with the instant access to servers and storage in the cloud, it’s easier than ever to spin up and manage your own cluster. If you haven’t heard too much about it yet, hadoop provides access to a distributed file system along with a framework for running map reduce jobs over the data. It takes care of replicating chunks of data to each node and running jobs in parallel for you. However, when you want to expand your hadoop cluster across availability zones you can run into some unexpected problems. So lets dig into the ideas we tried and the final solution that worked the best for our configuration.
The post Hadoop Across Availability Zones appeared first on Big Nerd Ranch.
]]>Hadoop is a great solution to the big data problem and with the instant access to servers and storage in the cloud, it’s easier than ever to spin up and manage your own cluster. If you haven’t heard too much about it yet, hadoop provides access to a distributed file system along with a framework for running map reduce jobs over the data. It takes care of replicating chunks of data to each node and running jobs in parallel for you. However, when you want to expand your hadoop cluster across availability zones you can run into some unexpected problems. So lets dig into the ideas we tried and the final solution that worked the best for our configuration.
Communicating across data centers is a pretty old problem with a lot of different solutions so we wanted to start out with the simplest thing we could think of. First, we decided to allow access by adding an elastic ip to each node and adding those addresses in the security group of the opposite availability zone. So this would basically just allow open communication from certain public addresses on the internet, which isn’t a bad solution. But if you ever need to replace or spin up a new node, it requires a decent bit of manual intervention to reassign the elastic ip or to create a new one and add it back to the security groups. Another downside is that, due to hadoop’s fancy hostname resolution, we can only utilize tasktrackers within the same availability zone as the namenode.
So next we tried using OpenVPN to create a bridge across the two networks, but there was one small problem. Because we didn’t have full control over what ip address our servers were assigned, there was the potential for two machines with the same ip on separate networks which would cause all kinds of weird problems. Amazon’s VPC can help solve this problem by giving you more control over the network but we decided to go a different route.
Instead of using a classic VPN solution, we gave tinc a try. Tinc is still considered a vpn daemon but instead of using it for a point to point connection, because it is so lightweight, you can install it on all of your servers and expose a new network interface to route traffic over. This allowed us to easily configure the vpn on the production system and then just switch the interface hadoop was listening on once everything was up and running. So here’s how we set it up.
Three files make up the basic configuration. The tinc-up script is responsible for creating the new network interface. The tinc.conf names the local node and keeps track of all the other nodes it needs to talk to. We also need a hosts file which is named after the local node we set in the tinc.conf. This file includes attributes for setting up the connection to the vpn like the external ip, vpn ip, vpn subnet and public key. Since we have everything already set up in chef we just set up a cookbook that ran a few searches across our servers and generated all the configuration files we needed. We also took advantage of hadoop’s rack awareness feature to make sure data is always streamed from the closest node and also makes sure replicas are spread across different data centers. There was only 1 problem that we came across which again involved hadoop’s hostname resolution. Map reduce jobs were periodically failing because the tasktracker would sometimes use the ec2 hostname and resolve the ip of a datanode incorrectly. So, we had to setup a tiny dns server to make sure that hostnames always pointed to correct tinc address. After fixing that everything worked great. We also had the added benefit of being able to connect through the vpn and access the files from hdfs directly using hue.
Since we quickly covered a lot of new technology, here are some useful resources for when you want to try this out yourself:
What other tips do you have on breaking the single availability zone barrier?
The post Hadoop Across Availability Zones appeared first on Big Nerd Ranch.
]]>In Ruby, blocks are kind of a big deal. We use them for everything from basic iteration to executing callbacks. They are also really handy for writing Domain Specific Languages, or DSLs for short. For example, checkout how blather uses blocks to respond to an XMPP message.
The post Using Block Scope for a Fancy DSL appeared first on Big Nerd Ranch.
]]>In Ruby, blocks are kind of a big deal. We use them for everything from basic iteration to executing callbacks. They are also really handy for writing Domain Specific Languages, or DSLs for short. For example, checkout how blather uses blocks to respond to an XMPP message.
We call the message method with some options and a block to execute when a message with those options is received. Blocks make this code a lot more fun to write because the event handler is hooked up behind the scenes. All we really have to worry about is what happens when we receive a specific message. So how would we implement this?
Without including the extra boiler plate to actually receive messages, it’s pretty simple code. We just register a callback and call it when the event happens. But, I want to take this a step further. If you’ve used sinatra, these examples involving blocks should look pretty familiar. Here’s an example of a simple get request definition to refresh your memory.
Cool! But how is this different from the blather message example? Look at the block we passed in. Notice anything different? We didn’t pass any parameters to the callback, but we used a params variable to get the beverage for the request. We never defined it in the scope before the block in our code. So, where did it come from? Since we always want to have a params hash in the callback of a request it makes sense that it would already be defined for us, but sinatra is actually doing some interesting things behind the scenes to make this happen. Let’s look at another example of how we would implement this DSL.
Now I wouldn’t use this all the time, but for cases like sinatra’s get requests, it can really make for an awesome DSL. Before you implement it in your own project, I would recommend reading over the docs for UnboundMethod and read though the sinatra source code just so you know exactly what’s going on. Since this article just skims the surface of what is important to know when building a DSL, here are a few resources that dig a little deeper:
What are some other resources and techniques you’ve used to make a great ruby DSL?
The post Using Block Scope for a Fancy DSL appeared first on Big Nerd Ranch.
]]>
The post Map Reduce Jobs in Ruby with Wukong appeared first on Big Nerd Ranch.
]]>
I recently got to work on some really interesting, big data problems at Highgroove. One of our clients needed to record every api call and analyze specific time periods for averages and usage metrics. Hadoop fits this use case pretty well with a distributed file system and map reduce framework built in. But, I’ll be honest, I wasn’t too happy about having to write map reduce jobs in Java. While looking for alternatives I found Wukong; a gem that adds a Ruby wrapper around the Hadoop Streaming utility. Here’s an example of how easy it makes writing map reduce jobs.
Now there are always trade offs. Streaming queries, especially to a Ruby script, are definitely slower than their pure Java counterparts. But, between the base startup time of any map reduce job (about 30 seconds) and the speed up from running all jobs in parallel across a cluster of workers, it’s really not that bad and totally worth the improvements in readability and maintenance. Also, because this script runs over the entire cluster, you have to make sure that each machine has the right ruby version and and all necessary gems installed, but we easily solved this with a few lines in a Chef recipe.
We’ve really only touched the surface of what is included with Wukong. There are plenty of different mapper and reducer classes depending on how you have your data structured and how you want to query it. With the script class provided by Wukong, you can run scripts across an entire Hadoop cluster with a single command. It even includes support for writing pig latin scripts in Ruby. So if you know Ruby and want to get involved with some big data projects, Wukong + Hadoop is a great way to get started.
The post Map Reduce Jobs in Ruby with Wukong appeared first on Big Nerd Ranch.
]]>If you’ve ever tried to integrate Jabber into your app or just wanted to write a bot to respond with TWSS jokes, you’ve probably checked out XMPP4R or Switchboard. These libraries are great and have a really solid feature set, but if you find yourself writing a lot of boilerplate and really want a library with more of a Ruby feel to it, try out sprsquish’s gem, Blather.
The post XMPP the Ruby Way appeared first on Big Nerd Ranch.
]]>If you’ve ever tried to integrate Jabber into your app or just wanted to write a bot to respond with TWSS jokes, you’ve probably checked out XMPP4R or Switchboard. These libraries are great and have a really solid feature set, but if you find yourself writing a lot of boilerplate and really want a library with more of a Ruby feel to it, try out sprsquish’s gem, Blather.
It’s written as a DSL and leverages Eventmachine, which allows you to easily listen for messages and send a response. Checkout how simple it is to get up and running:
====
There are tons of ways to filter out messages by checking attribute values, matching a regular expression, or even passing in a custom Proc. You can also respond to most other events like presence notifications and even file transfer requests. The gem is also really well organized so you can easily work at the Eventmachine layer or just use their nicely defined DSL with command line options to get up and running as quick as possible.
There are instructions on how to get it installed in the README along with some example scripts in the repo. If you’re planning on using it with a web app here’s a quick example that we used in our tech demo of how to run it along side Sinatra using Foreman.
The post XMPP the Ruby Way appeared first on Big Nerd Ranch.
]]>