The post Contact Tracing: 7 Ways Google and Apple are Protecting User Privacy appeared first on Big Nerd Ranch.
]]>During an epidemic or a pandemic, contact tracing is part of the routine protocols followed by a health organization. Traditionally, this has been a very manual process, whereby a healthcare-worker interviews a patient with a positive diagnosis to track their whereabouts prior to the diagnosis. The goal is to create a list of people the patient came in contact with and to notify them of the exposure so they too can get tested. Given that we live in a world where everyone carries a smartphone, technology can potentially facilitate this function easily and efficiently.
Contact Tracing vs. Exposure Notifications
During this global pandemic, many countries have created their own solution to digital contact tracing, though many of these technical solutions have privacy concerns. Not to mention that the name “contact tracing” itself has a big brother connotation to it, which elicits the notion of a nanny state. Google and Apple have joined forces to create a privacy-preserving contact tracing solution. They have stated that user privacy and security are central to the design of their contact tracing capabilities. This is reflected in Apple’s and Google’s careful naming of the technology called Exposure Notifications rather than Contract Tracing. Furthermore, their design gives a user fine-grained control over permissions.

At a high level, devices are essentially using Bluetooth to exchange some data. Exposure Notification leverages Bluetooth Low Energy (BLE) to transmit data to nearby devices. The transmission of data via BLE is known as a beacon. The beacon contains a randomized string of numbers that changes every 15 minutes. The device is constantly broadcasting beacons while scanning for beacons from other devices. When a device comes near another device broadcasting the Exposure Notification beacons it stores them locally on the device. At least once a day, the device downloads a list of keys for the beacons that have been identified as belonging to people with a confirmed positive diagnosis. Each device locally matches the beacons it has stored against the ones downloaded from the server to see if there is a match to confirm exposure. Once confirmed, the user is notified of the exposure and advised on the next steps.
Exposure Notifications: User Privacy in the Data Exchange
Let’s dive deeper to find out how the Exposure Notification API preserves the user’s privacy in this beacon data exchange:
- Bluetooth only: Some contact tracing solutions have resorted to using GPS and Bluetooth. The drawback of using GPS is that it is a major privacy violation because it is constantly monitoring a user’s every move. Exposure Notifications rely solely on Bluetooth and don’t exchange any personally identifiable data, and so it gets points for privacy. The drawback of only using Bluetooth is that you might risk having more false positives, meaning a person was notified that they were exposed when they weren’t, however that is a separate topic of discussion.
- User Opt-in: The technology provides an end-user complete control over whether they want to participate or not. Opting-in is as easy as turning on a toggle switch within the settings app. You will not be required to install an app to access these settings as it will be part of the OS. Even after a user has opted in, they have the power to delete the exposure logs, which contains a list of beacons stored on the device. If the user does not delete the logs manually, they are automatically erased after 14 days.

- Broadcasting: The device is continuously broadcasting beacons to share data with other devices. The beacon data consists of three pieces of information in its payload:
- Exposure Notification Service UUID: this is a service identifier used by the Bluetooth service when scanning for Exposure Notification beacons.
- Rolling Proximity Identifier (RPI): contains a randomized string of numbers that changes every 15 minutes. This number is derived using the Temporary Exposure Key, which is a key generated every 24 hours. The RPI gets broadcasted to devices in the vicinity as part of the beacon payload but not the Temporary Exposure Key.
- Associated Encrypted Metadata (AEM): contains protocol versioning and transmit power for distance approximation. The transmission power is the Received Signal Strength Indicator or RSSI, which is part of the Bluetooth protocol. AEM along with the RPI synchronously gets updated every 15 minutes as well to avoid any tracking.
- Scanning: when scanning for Exposure Notification beacons, the device is searching for beacons with the specific Exposure Notification Service UUID. If found, it receives the beacon payload containing the PRI and AEM, which are stored locally on the device along with a timestamp.
- Diagnosis submission: When a user receives a positive diagnosis, they have to enter their diagnosis within an app. Prior to submitting the positive diagnosis, the user is asked for permission, once authorized, the app submits their diagnosis keys to a server. The diagnosis keys are a subset of Temporary Exposure Keys which are sent to a centralized server hosted by the creators of the app. Future releases of Exposure Notifications will not require a central server as it will be hosted by Apple/Google.
- Exposure: the final piece of the puzzle is determining whether the user was exposed to a person with a positive diagnosis. At least once every 24 hours, the device downloads all the Diagnosis Keys from the server. These are the keys that were submitted when a user received a positive diagnosis. The Diagnosis Keys are a subset of the Temporary Exposure Keys, which are used to generate RPIs. The RPIs generated are using the keys from the server and are matched against the RPIs stored locally on the device. When a match is found, a Risk score is calculated based on factors such as days since the exposure incident, cumulative duration of the exposure days, Bluetooth signal strength, and a transmission value which is a level of diagnosis verification or other determination from the app/health authority. The calculation of the Risk score and matching of keys are all conducted on the device. Upon finding a match, the end-user is notified that they were exposed to the virus. This information is never sent to the server. Finally, if the exposed user is diagnosed positive they will have to manually self-identify.
Conclusion
Upon examining all the pieces from opting-in, broadcasting beacons, scanning beacons, diagnosis submission, and finding a match, we find that Apple and Google have built privacy protections for individuals at many key steps in the data flow. The implementation, however, is not without some risk. Specifically, in the first phase of the rollout of Exposure Notifications, Apple and Google require developers of the app to host a centralized server of their own to store the diagnosis keys. In the second phase, the server requirement is eliminated because Apple and Google take on that burden themselves.
Contact tracing apps are already being built without a standard of privacy set; regardless of the efficacy of contact tracing as a solution, there’s a moral responsibility to build these apps with privacy in mind. It appears Apple and Google are taking this responsibility seriously as they pioneer their Exposure Notification APIs.
Curious about building an app with Exposure Notifications? Get in touch and let’s see how we can partner together to keep people’s health and privacy safe and sound by leveraging Exposure Notifications
The post Contact Tracing: 7 Ways Google and Apple are Protecting User Privacy appeared first on Big Nerd Ranch.
]]>The post A Brief Tour of Swift UI appeared first on Big Nerd Ranch.
]]>The best user interfaces are interactive and responsive to the user. UIKit is a capable framework that lets you build apps that users expect, but it can be tedious at time, not to mention having the flavor of an Objective-C toolkit.
SwiftUI takes advantage of Swift’s modern language features, giving us a modern framework that hits modern programming buzzwords.
It’s Declarative. Describe your UI in broad strokes using simple code.
It’s Compositional. You take existing views and connect them together and arrange them on the screen as you want.
It’s Automatic. Complex operations, like animations, can be done as a one-liner.
It’s Consistent. SwiftUI can be run on all of Apple’s platforms. It will take care to configure your UI (such as padding distance between on-screen controls, or dynamic type)
so that it feels at home on whatever platform it’s running, whether it’s a Mac or the AppleTV.
Views and View Modifiers
Views are the heart of SwiftUI. According to Apple:
Views are defined declaratively as a function of their input
A View in SwiftUI is a struct that conforms to the View protocol. They are unrelated to UIViews (which are classes). A SwiftUI View is a value type, composed of the data that explains what you want to display.
Here’s a simple view:
struct SimpleView : View {
var body: some View {
Text("I seem to be a verb")
}
}
Here SimpleView conforms to the View protocol. To appease the protocol, you need to provide a body, which is an opaque type. By using some new syntax, some View, we’re declaring that body is some kind of View, without having to specify a
concrete type. Check out Swift Evolution Proposal 244 for more about opaque types.
The body is some View that describes what should be on the screen. In this case it’s a simple text label with a default configuration. Your body can be composed of multiple Views, such as a stack that arranges images horizontally.
Because body is a View, and it’s an opaque type, nobody really cares if a given View ends up being a single on-screen entity or a bunch of views composed in a stack or a list. This lets us compose complex hierarchies easily.
Chain Reaction
SwiftUI Views are value types, so we really don’t have stored properties to modify their look and feel. We need to declare our look and feel intentions to customize our views.
SwiftUI has ViewModifiers, such as .foreground to change the foreground color or .font to change a view’s font, that applies an attribute to a View. These modifiers also return the view they’re modifying, so you can chain them:
Text("SwiftUI is Great!")
.foreground(.white)
.padding()
.background(Color.red)
This declarative syntax is very easy to read, letting you accomplish a lot with little code.
")
Stacks
You can build hierarchies of views. In UIKit, we use UIStackView to make vertical and horizontal stacks of UIViews. In SwiftUI, there’s an analogous HStack and VStack views that let you pile views horizontally or vertically.
This view positions one label above another.
VStack {
Text("Swift UI is Great!")
.foreground(.white)
.padding()
.background(Color.red)
Text("I seem to be a verb")
}
There’s also ZStack that lets you stack views on top of each other, like putting a label on top of an image.
You’re welcome to nest multiple stacks to compose complex view hierarchies. The stack views will automatically provide platform-appropriate defaults and if you don’t like the defaults, you can provide your own alignment and spacing.
Lists
SwiftUI lists look like tableviews in UIKit. In SwiftUI, the framework does the heavy lifting, freeing you from data source boilerplate.
Setting up a list with hard-coded views is really easy. Setting it up is exactly like setting up a stack:
struct ListView : View {
var body: some View {
List {
Text("Look")
Text("A")
Text("TableView")
}
}
}
The views inside the closure of a list serve as static cells.
The List also has an optional data parameter (that conforms to the Identifiable protocol) where you can provide some data to drive the creation of the cells inside the table.
Here’s a struct of a contact:
struct Contact: Identifiable {
let id = UUID()
let name: String
}
Having a unique identifier in your identifiable data helps with list selection and cell manipulation.
And here’s a View that hardcodes a list of contacts:
struct ListView : View {
let contacts = [Contact(name: "Arya"), Contact(name: "Bran"), Contact(name: "Jon"), Contact(name: "Sansa")]
var body: some View {
List(contacts) { contact in
Text(contact.name)
}
}
}
This is the magic bit:
List(contacts) { contact in
Text(contact.name)
}
This is telling the list: “for every Identifiable in this list of contacts, make a new Text view whose text contents are the contact’s name. You can add new folks to contacts, and the list will contain more rows.
State and Binding
Static hard-coded lists are great for initial prototyping of your ideas, but it’d be nice for the list to be dynamic, such as populating it with data from the internet. Or insert and
delete new rows, and to rearrange things.
WWDC 2019 session 226 Data Flow Through SwiftUI tells us:
In SwiftUI data is a first class citizen
To manage state within our app, SwiftUI provides stateful binding to data and controls using property wrappers. Check out Swift Evolution Proposal
258 for more about property wrappers.
Here we’re using the the @State property wrapper to bind an isEnabled property to a toggle control:
struct EnabledTogglingView : View {
@State private var isEnabled: Bool = false
var body: some View {
Toggle(isOn: $isEnabled) {
Text("Enabled")
}
}
}
Another quote from session 226, Data Flow Through SwiftUI:
SwiftUI manages the storage of any property you declare as a state. When the state value changes, the view invalidates its appearance and recomputes the body.
The state becomes the source of truth for a given view.
@State is great for prototyping, and for properties that are intrinsic to a view (such as this enabled state). To actually separate your data layer from your view layer, you need BindableObject.
So say we’re setting up a preference panel, or some kind of configuration panel with a sequence of toggle buttons. First, a model object for each individual setting:
class Settings: BindableObject {
var didChange = PassthroughSubject<Bool, Never>()
var isEnabled = false {
didSet {
didChange.send(self.isEnabled)
}
}
}
Notice that Settings is a reference type (a class), which conforms to the BindableObject protocol. The PassthroughSubject doesn’t maintain any state – just
passes through provided values. When a subscriber is connected and requests data, it will not receive any values until a .send() call is invoked.
struct BindableToggleView : View {
@ObjectBinding var settings: Settings
var body: some View {
Toggle(isOn: $settings.isEnabled) {
Text("Enabled")
}
}
}
take another look at this line of code:
@ObjectBinding var settings: Settings
That’s weird. It’s not an optional then what’s it initialized to? Well, because settings is declared with the @ObjectBinding property wrapper, this tells the framework that it will be receiving data from some bindable object outside of the view. This object binding doesn’t need to be initialized.
You inject a BindableObject into the View that should use it. Here’s how our Settings gets hooked up to this BindableToggleView:
BindableToggleView(settings: Settings())
Your view does not care where the data lives or how it is populated disk, cache, network, osmosis. The view simply knows that it will be binding to some object when available.
The @ObjectBinding property wrapper creates a two-way binding. Whenever a mutation occurs the view automatically re-renders.
@ObjectBinding requires dependency injection to provide the data object. That can be inconvenient.
To make this object available anywhere within your app without dependency injection you can use the environment. New with SwiftUI you have an environment object that contains all kinds of information like screen size, orientation, locale, date format, etc. If you stick an object into the environment then that object can be accessed anywhere within your app. Think of it as a dictionary that is globally scoped within your app.
So how do you use it? The @EnvironmentObject property can help you with this.
struct BindableToggleView : View {
@EnvironmentObject var settings: Settings
var body: some View {
Toggle(isOn: $settings.isEnabled) {
Text("Enabled")
}
}
}
In the above example, everything remains the same as seen previously, except you replace @ObjectBinding with @EnvironmentObject.
To inject an object into the environment you call the .environmentObject method.
ContentView().environmentObject(Settings())
An instance of Settings is now injected into the environment and is available to you anywhere within your app. When the object mutates then every view bound to it will receive the update and re-render its view. You no longer have to maintain a mental model of all the dependency-injections to keep your user interface in sync.
Animation
Animations in SwiftUI work like any view modifier. Basic animations can be achieved using the withAnimation method.
Here’s a View with two text labels:
struct ContentView: View {
@State var scale: CGFloat = 1
var body: some View {
VStack {
Text("This text grows and shrinks")
.scaleEffect(scale)
Text("Scale it")
.tapAction {
self.scale = self.scale == 1.0 ? 5.0 : 1.0
}
}
}
}
Tapping the second text label alters the size of the first text label, alternating its size between normal and five-times larger. The scaling happens instantly without any animation.
It’s a one-liner to make it animate smoothly.
Text("Scale it")
.tapAction {
withAnimation {
self.scale = self.scale == 1.0 ? 5.0 : 1.0
}
}
withAnimation can take an argument that lets you customize the animation. You can call it with a .basic animation, or you can have more fun with .spring animation that gives you control to make a beautiful spring effect.
Conclusion
SwiftUI is a delight to use. The focus is on creating an app because SwiftUI gets out of your way, taking care of a lot of annoying details. Design rich, interactive user interfaces by composing reusable views. Ensure data is coming into the system and not worry about keeping the view and model layers in sync. Finally, easily add animations to make views come alive. If you’re interested to learn more about iOS development & Swift programming, stay updated with our books & bootcamps.
The post A Brief Tour of Swift UI appeared first on Big Nerd Ranch.
]]>The post Getting Started with Deferred appeared first on Big Nerd Ranch.
]]>At Big Nerd Ranch, we have created a library called Deferred, which makes it easier for developers to work with data that is not yet available but will be at some point in the future. For example, when you’re downloading data from the network or parsing data, the data is not yet available because some work needs to be completed first. You might know this concept as Futures or Promises, but if not, don’t worry—this post will help you gain a better understanding.
Status Quo
Most iOS apps have to deal with asynchronous tasks, such as networking or some kind of processing. Every iOS developer knows better than to block the main UI with some time-consuming task. We do this by adopting either the delegation pattern or the completion handler pattern.
Delegation
protocol DownloaderDelegate: class {
func downloadDidFinish(with data: Data?, by downloader: Downloader)
}
This pattern works fine when our application is simple, but as the complexity increases, we’re driven to coordinate multiple delegates, which gets harder and more error-prone as delegate callbacks continue to multiply.
Completion Handler
You say that delegation is an old pattern and I use completion handlers (callbacks), which is fantastic. Instead of the delegate example from the last section, you’d write something like this:
func download(contentsOf url: URL, completion: @escaping (Data?) -> Void)
This is a lot better because you are capturing scope and passing a closure. It’s modern code that is easier to read. But how do you manage multiple asynchronous blocks of code that are dependent on each other? You end up with nested callbacks.
That’s an acceptable solution at first. You say you just need to download an image? The completion handler works great. However, in the long run, when you need to download an image, turn it into a thumbnail if it’s bigger than a certain size, rotate it, and run it through a filter to increase contrast, well, suddenly it gets a lot more painful. You end up with a rat’s nest of logic along with a pyramid of doom:
// nested callbacks or pyramid of doom
download(contentsOf: url) { data in
let downloadedImage = ...
downloadedImage.resizeTo(...) { resizedImage in
resizedImage.rotateTo(...) { rotatedImage in
rotatedImage.applyFilter(...) { finalImage in
// so something with the final image
}
}
}
}
Introducing Deferred
Asynchronous programming involves waiting for a value. This value could be downloaded from the network, loaded form the disk, queried from a database or calculated as a result of a computation. Before we can pass this value around, we need to wait till it exists. This is where we get into the issue of nested callbacks or completion handlers, which are useful, but not the most effective style of programming, because as the code complexity increases, it degrades the readability of the code.
A Synchronous Starting Point
What if we were able to pass around a value without having to worry about its existence? Let’s say we needed to download data from the network and display it in a list. We first need to download that data, parse it and then ready it for display:
let items = retrieveItems()
datasource.array = items
tableView.reloadData()
An Asynchronous Version
The above code represents a very basic version. It relies on a synchronous retrieveItems call that will block your UI until data is available. We can write an asynchronous version of the same code which would look something like the following:
retrieveItems { items in
DispatchQueue.main.async() {
datasource.array = items
tableView.reloadData()
}
}
In both the sync and async cases, we have to explicitly call the method to retrieve items and we cannot pass around items until we have a value. In essence, the array of items is something that will exist in the future, and the method retrieveItems promises to provide it to us.
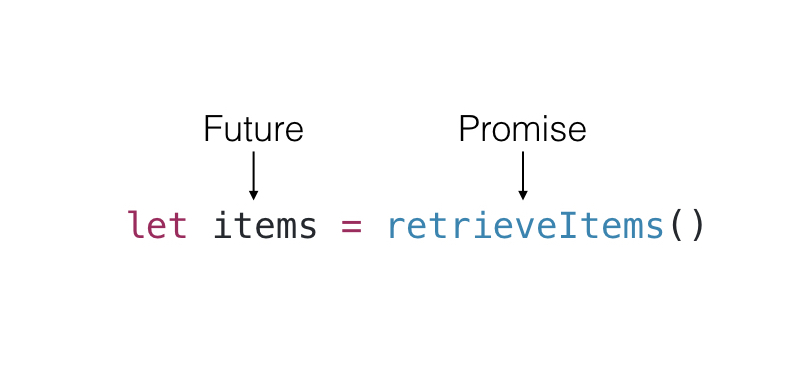
Rewriting with Deferred
Deferred uses the idea of futures and promises to defer providing a value. Since we are dealing with Swift, these concepts map easily to the type system, where we can model both a future and a promise with generics:
Future<T>– read-only placeholder for a value of typeTPromise<T>– write-once container for a value of typeT
Let’s try recreating our previous example using Deferred:
import Deferred
let deferredItems = Deferred<[Item]>()
Here we are simply saying that we are creating a type Deferred which will provide us with an array of items. The great thing about Deferred is that you can chain one or many calls to upon each of whose closure argument will execute once we have a value:
import Deferred
let deferredItems: Deferred<[Item]>()
deferredItems.upon(DispatchQueue.main) { items in
datasource.array = items
tableView.reloadData()
}
The upon method’s first argument determines where the closure will execute once the value arrives. Here, we’ve aimed it at the main queue. When displaying the items we are only concerned with what we are going to do once the items are available. The closures is not worried about how or when to retrieve the items or where the retrieval should execute.
Elsewhere in your app you can retrieve those items and then fill them in your Deferred object.
deferredItems.fill(with: retrieveItems())
The above code is focused on providing a value to your deferredItems. You could easily make retrieveItems asynchronous with a completion handler filling in the value:
//Asynchronous example
retrieveItems { items in
deferredItems.fill(with: items)
}
upon tells Deferred that the closure is waiting to run whenever it gets filled. When a Deferred gets filled with a value, all the waiting closures get called with that value. (And if it never gets filled, they never run.)
Result Type
The above example does not take errors into consideration, but anything can go wrong when making a network request. So how do you handle errors with Deferred? Remember that Deferred represents a value of any type. If there’s no chance of error, you’d use a Deferred<Value> to say that you expect to eventually deliver a value. But very few things are certain, so to represent the possibility of eventually discovering either a value or an error, we typically use the Result type:
enum Result<SuccessValue> {
/// Contains the value it succeeded with
case success(SuccessValue)
/// Contains an error value explaining the failure
case failure(Error)
}
The same example using a Result type would look like the following:
import Deferred
let deferredItems = Deferred<Result<[Item]>>
deferredItems.upon(.main) { result in
switch result {
case let .success(value):
datasource.array = value
tableView.reloadData()
case let .failure(error):
print(error)
}
}
You don’t have to create your own Result type because the Deferred framework provides you with one.
Note that in the above example, we use .main when passing a parameter to upon, instead of DispatchQueue.main since DispatchQueue is implied. Either is acceptable, but the latter makes your code more readable.
Learn More About Deferred
There is more you can do with Deferred like chaining async calls, or running a closure till several Deferreds have been filled. It even has a Task type for reporting progress or cancelling a task. To find out more, check out the documentation or—even better!—attend one of our Advanced iOS bootcamps.
The post Getting Started with Deferred appeared first on Big Nerd Ranch.
]]>